Launch a dedicated cloud GPU server running Laboratory OS to download and run Wan 2.1 I2V 14B 480P using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Model Report
Wan-AI / Wan 2.1 I2V 14B 480P
Wan 2.1 I2V 14B 480P is an image-to-video generation model developed by Wan-AI featuring 14 billion parameters and operating at 480P resolution. Built on a diffusion transformer architecture with T5-based text encoding and a 3D causal variational autoencoder, the model transforms static images into temporally coherent video sequences guided by textual prompts, supporting both Chinese and English text rendering within its generative capabilities.
Explore the Future of AI
Your server, your data, under your control
Wan 2.1 I2V 14B 480P is a component of the Wan 2.1 suite of large-scale generative models designed for video synthesis and editing. This model supports image-to-video generation at 480P resolution, featuring a 14 billion parameter architecture. Wan 2.1 models support diverse generative tasks—ranging from text-to-video, image-to-video, and first-last-frame-to-video synthesis to video editing and text-to-image generation—and include integration of visual text rendering in both Chinese and English, which broadens their practical application scope, as described in the Wan 2.1 Technical Report.
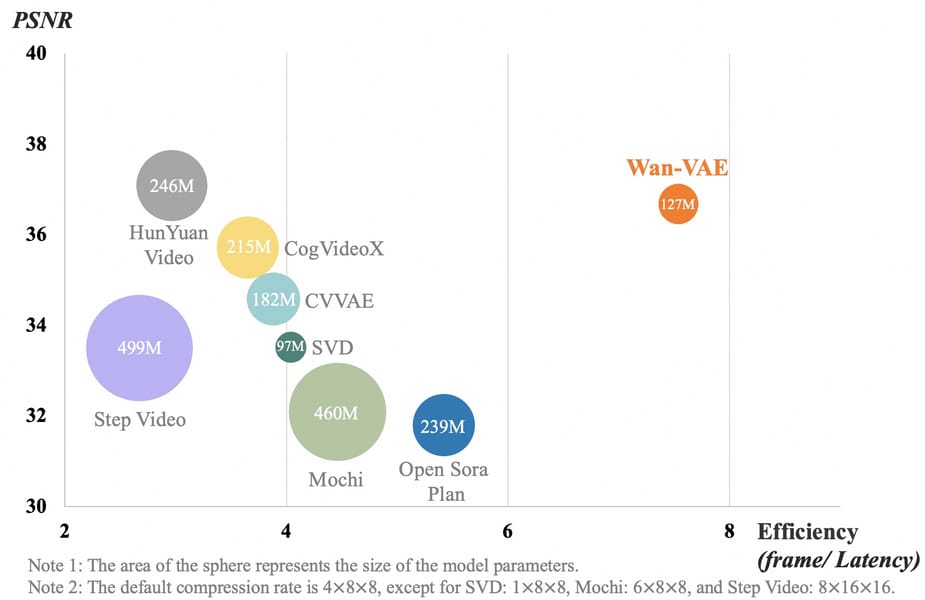
A comparative analysis illustrating the spatio-temporal compression and efficiency of the Wan-VAE architecture used in Wan 2.1, benchmarked against other video generative models.
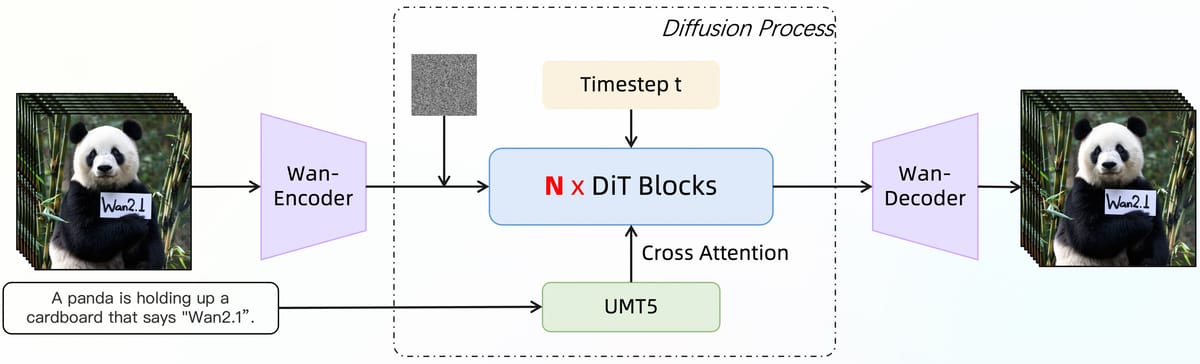
Wan 2.1 I2V 14B 480P is built on a diffusion transformer paradigm, incorporating a T5-based text encoder for multilingual support, a series of DiT (Diffusion Transformer) blocks with cross-attention, and a 3D causal variational autoencoder (Wan-VAE) for efficient spatio-temporal encoding and decoding, as detailed in the Wan 2.1 GitHub repository. The architecture enables the simultaneous processing of image and text prompts and the preservation of temporal consistency across generated video frames.
Schematic of the Wan 2.1 diffusion-based video generation pipeline, highlighting the role of the T5 encoder, DiT blocks, and the iterative denoising process within the diffusion framework.
The 14B variant utilizes a transformer stack with a dimensionality of 5120, 40 layers, and 40 attention heads, supported by a feedforward network dimension of 13,824 and fixed frequency embedding. This configuration enables high-quality, efficient video synthesis, while the underlying 3D causal Wan-VAE encoder ensures both memory efficiency and temporal fidelity, according to its Hugging Face Model Card.
Data Curation and Training Methodology
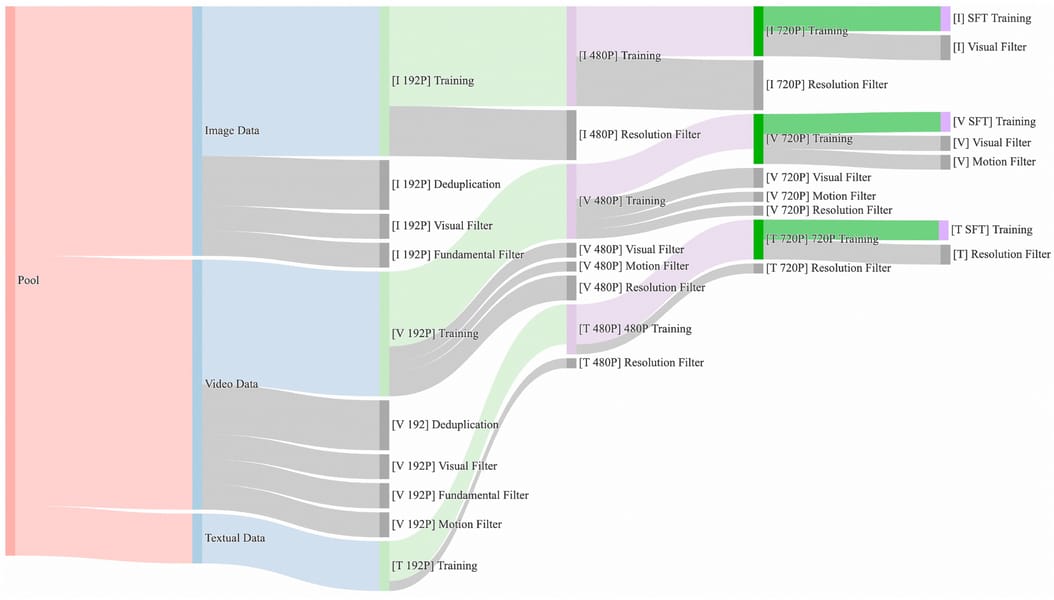
Training of Wan 2.1 I2V 14B 480P relies on curated and deduplicated multimodal datasets, encompassing large-scale image and video content. The data pipeline applies filtering operations along multiple quality axes—including visual integrity, motion realism, and resolution consistency—via a multi-step cleansing and augmentation process. Datasets are systematically structured to support both supervised fine-tuning (SFT) and unsupervised pretraining, ensuring diversity and representativeness, as documented in the Wan 2.1 Technical Report.
Sankey diagram depicting the comprehensive data curation pipelines for constructing the high-diversity training corpora used in Wan 2.1.
The multi-stage filtration ensures that examples with high visual and motion quality enter the training process, which contributes to the temporal and perceptual coherence of the generated videos.
Performance and Evaluation
Wan 2.1 I2V 14B 480P has undergone extensive benchmarking using both quantitative metrics and expert evaluations. Across various tasks, including text-to-video and image-to-video synthesis, the model yields quantitative scores in evaluation domains such as large motion generation, pixel-level stability, ID consistency, and action instruction following, as outlined in the Wan 2.1 Technical Report.
Comparison of the Wan 2.1 14B model versus other video generation models on multiple evaluation axes, including physical plausibility and stylization ability.
Manual evaluations indicate that the model performance is comparable to or surpasses other solutions across benchmarks, particularly when prompt-extension methods are utilized to refine the input, based on the Wan 2.1 Technical Report.
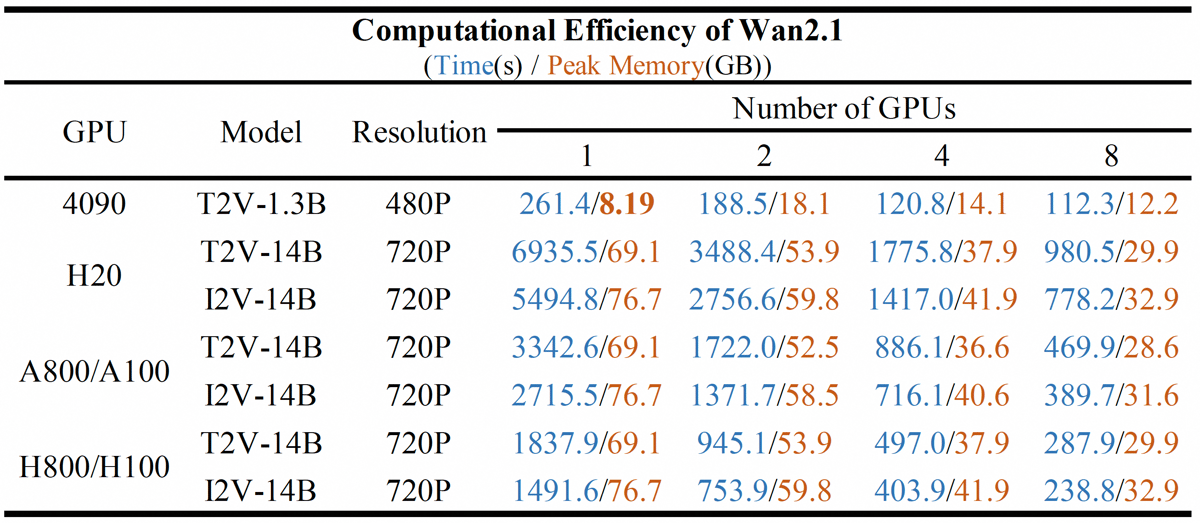
Computational efficiency is a specific design consideration for this model. For the I2V 14B 480P variant, generation of a 480P video segment can be achieved on GPUs within typical timeframes, with memory optimizations further reducing resource requirements. The model also scales with multi-GPU setups, making distributed and accelerated inference feasible.
Summary of inference times and peak GPU memory consumption for Wan 2.1 models across different hardware configurations.
Demonstration video highlighting the generative and editing capabilities of Wan 2.1 I2V 14B 480P and related models. [Source]
Applications and Model Outputs
Wan 2.1 I2V 14B 480P is designed for image-to-video synthesis, enabling the transformation of a single input image into a temporally coherent video sequence, often guided by additional textual prompts. The model's architecture also allows for cross-modal tasks—including video editing, first-last-frame-to-video synthesis, and text-to-image generation within the same ecosystem, as documented on the Wan 2.1 Official Website.
Sample AI-generated output from Wan 2.1 I2V 14B 480P, illustrating realistic scene synthesis from an image and prompt.
The model is used in creative applications, short video production, animation generation, and contexts where image-to-video transformation is essential.
Limitations and Model Family
While Wan 2.1 I2V 14B 480P functions at 480P resolution, some constraints are observed when pushing to higher resolutions or utilizing smaller models. For instance, the 1.3B parameter variant provides less stable results at high resolution due to limited training. The FLF2V extension, primarily trained on Chinese-language pairs, may yield better results for prompts in Chinese, according to the Hugging Face Organization page for Wan-AI.
Wan 2.1 models are released under the Apache 2.0 license, encouraging open research and community contribution while specifying user responsibilities regarding content generation and compliance.