Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek V2.5 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek V2.5
DeepSeek V2.5 is a 236 billion parameter Mixture-of-Experts language model that activates 21 billion parameters per token during inference. The architecture incorporates Multi-head Latent Attention for reduced memory usage and supports both English and Chinese with an extended context window of 128,000 tokens. Training utilized 8.1 trillion tokens with subsequent supervised fine-tuning and reinforcement learning alignment phases.
Explore the Future of AI
Your server, your data, under your control
DeepSeek V2.5 is a large-scale Mixture-of-Experts (MoE) language model developed by DeepSeek-AI, designed to facilitate efficient training, inference, and multilingual performance in large language modeling. Introduced as the successor to DeepSeek 67B, DeepSeek V2.5 implements architectural innovations that influence benchmark performance, operational costs, and long-context natural language understanding. Its design combines attention mechanisms, parameter efficiency, and scalable routing strategies to facilitate both English and Chinese language proficiency, as detailed in the technical report and arXiv preprint.
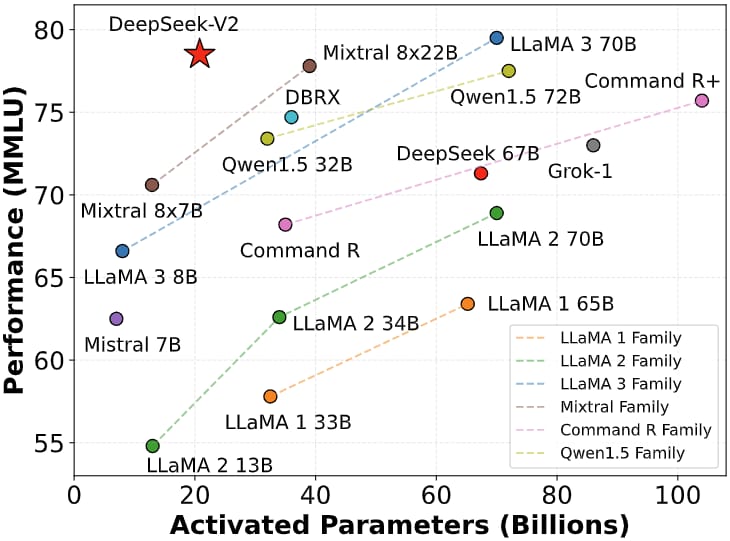
A scatter plot highlighting DeepSeek-V2’s parameter efficiency (activated parameters per token vs. MMLU performance), contrasted with other leading language models.
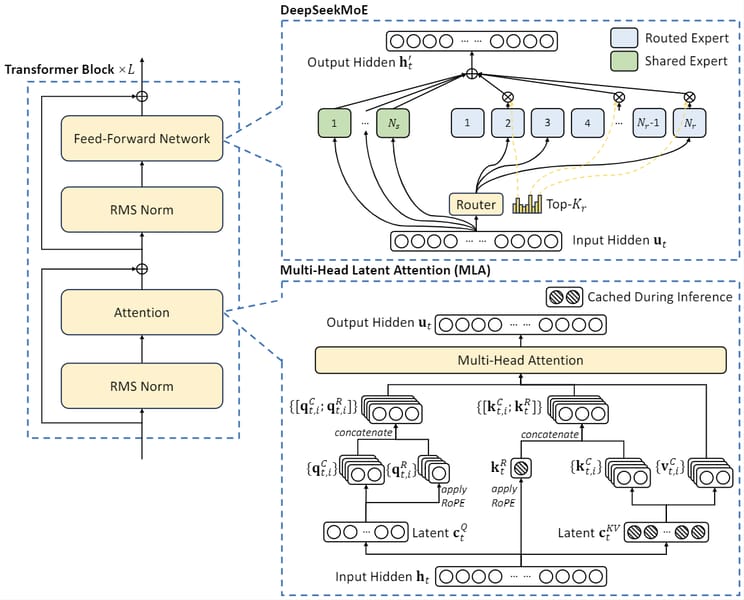
DeepSeek V2.5 is built on a Transformer-based backbone with modifications intended to optimize computational overhead and scale. The model architecture introduces Multi-head Latent Attention (MLA), which incorporates low-rank key-value compression to reduce memory requirements during inference, thereby addressing the KV cache bottleneck that often constrains large models. This mechanism compresses keys and values into a shared latent representation, reducing cache size and enabling efficient transformer self-attention computation.
The DeepSeekMoE framework is also integrated into the architecture. In this Mixture-of-Experts arrangement, the model consists of 236 billion total parameters, with 21 billion parameters activated per token. Experts are segmented finely to facilitate specialization, and a dedicated routing system ensures that the computational and communication load is distributed across devices efficiently. Auxiliary loss mechanisms at both expert and device levels—along with a communication balance component—are employed to prevent routing collapse and to balance computational efficiency.
A novel device-limited routing strategy restricts the set of active experts for each token to a maximum number of hardware devices, controlling communication cost during parallel processing. Further, a token-dropping method helps maintain load balance on each device during training. The model’s position encoding utilizes a decoupled Rotary Position Embedding (RoPE) strategy, addressing challenges introduced by low-rank compression techniques.
Technical diagram of DeepSeek-V2, illustrating its Multi-head Latent Attention (MLA) and DeepSeekMoE architecture as well as the overall Transformer block design.
Pretraining of DeepSeek V2.5 utilized a corpus of 8.1 trillion tokens, with a focus on bilingual (Chinese and English) coverage. The dataset curation process includes filtering to enhance linguistic quality and to minimize bias arising from regional and topical imbalances. Compared to its predecessor, DeepSeek V2.5 employs a modified data selection algorithm and a pretraining corpus with a higher proportion of Chinese language data.
The tokenizer used is based on Byte-level Byte-Pair Encoding (BBPE) with a 100,000-word vocabulary. Pretraining optimizations include a 60-layer Transformer stack, 128 attention heads per layer, and both shared and routed experts in each MoE layer. After the initial pretraining, context length is extended from 4,000 to 128,000 tokens using the YaRN (Yet another RoPE extension) method, which is specifically adapted for the positional embedding in long-context scenarios.
Alignment is conducted over two main stages. First, supervised fine-tuning leverages 1.5 million conversational interactions covering math, code, writing, reasoning, and safety. In the second stage, preference alignment is achieved via reinforcement learning using Group Relative Policy Optimization (GRPO, aiming to influence output characteristics such as helpfulness and safety through a reward modeling strategy.
Performance and Evaluation
DeepSeek V2.5 performance is evaluated on a range of standard large language model benchmarks across English and Chinese. When compared to other contemporary models, its performance on benchmarks is achieved while operating with a relatively lower proportion of activated parameters per token.
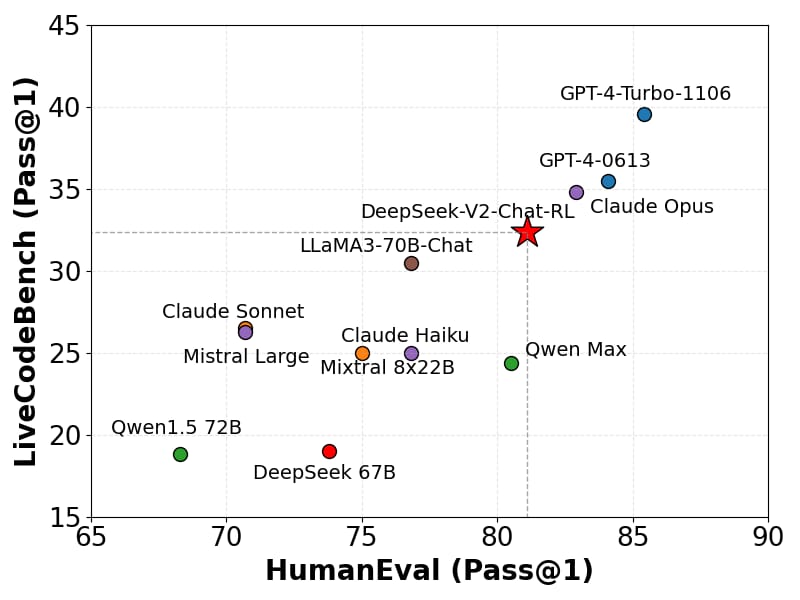
Benchmarks reveal the model’s efficacy on language understanding and reasoning tasks (such as MMLU, BBH, C-Eval, and CMMLU) as well as its code generation capabilities (HumanEval, MBPP, and LiveCodeBench). For mathematical problem-solving, evaluations on GSM8K and MATH datasets illustrate its reasoning skills.
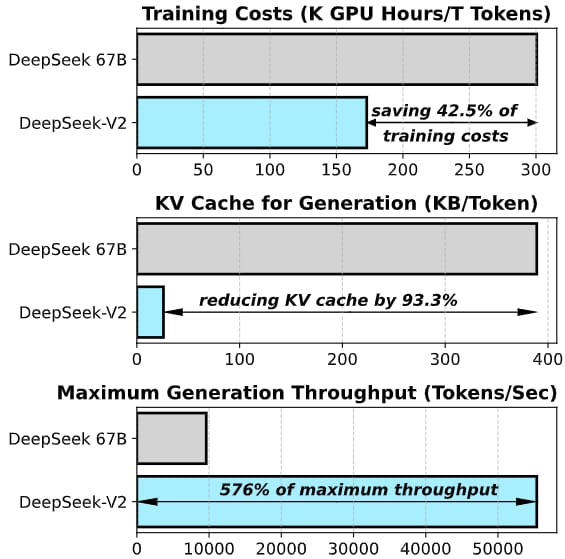
Comparative analysis of DeepSeek-V2 versus DeepSeek 67B, showing reduced training costs, lower KV cache requirements, and higher generation throughput.
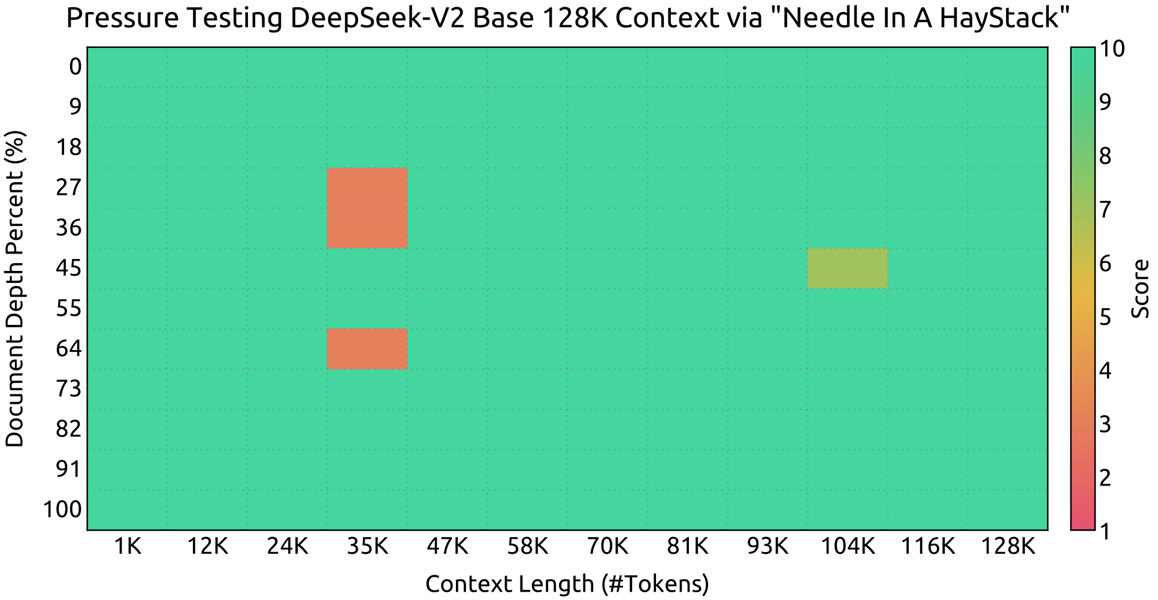
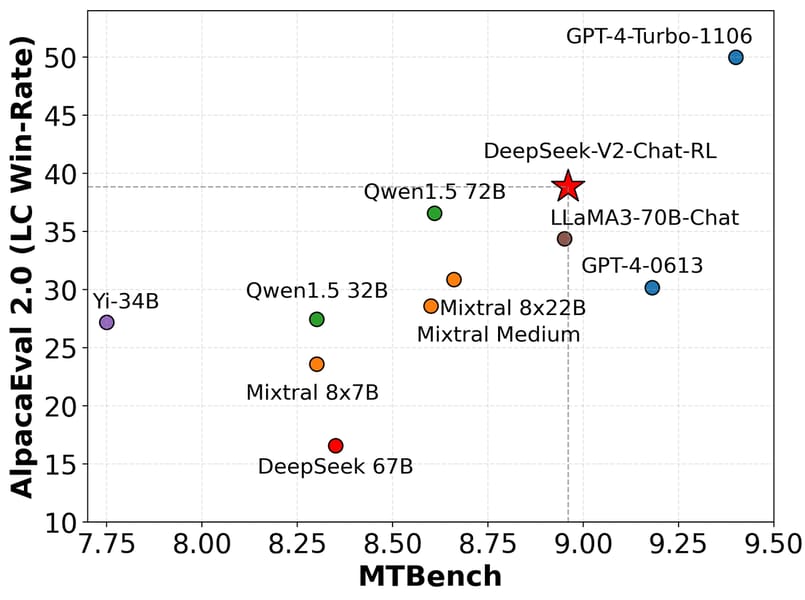
The model retrieves specific information from long sequences, as indicated by its NIAH test results. The chat variant (DeepSeek-V2-Chat) is evaluated on MTBench and AlpacaEval 2.0, with results comparable to open and closed-source conversational models.
Evaluation of DeepSeek-V2-Chat (RL) in open-ended English generation, visualized by MTBench and AlpacaEval 2.0 win-rates compared to other models.
DeepSeek V2.5 is suitable for a range of tasks, including general text generation, open-domain conversation, code completion and synthesis, mathematical reasoning, and bilingual applications in English and Chinese. Its extended context window supports processing of long documents, making it relevant for summarization and information retrieval tasks.
DeepSeek V2.5 retains limitations typical of large pretrained models: post-training knowledge is static, and the possibility remains for generating inaccurate or misleading information. The model's performance focus is on Chinese and English; proficiency in other languages may be limited due to the training data’s linguistic composition. At present, DeepSeek V2.5 operates exclusively in the text modality.
Licensing and Model Family
DeepSeek V2.5 is distributed under the MIT License for code, while the model weights are governed by a custom Model License Agreement, permitting research and commercial use. A smaller-scale variant, DeepSeek-V2-Lite, with 15.7 billion parameters, is also available, which can be used for community exploration and research.