Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek R1 Distill Qwen 14B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek R1 Distill Qwen 14B
DeepSeek R1 Distill Qwen 14B is a dense text generation model developed by Deepseek AI, distilled from the larger DeepSeek-R1 mixture-of-experts model. Built on the Qwen2.5-14B architecture, it specializes in mathematical reasoning, code generation, and logical problem-solving through supervised fine-tuning on approximately 800,000 curated reasoning samples from its teacher model.
Explore the Future of AI
Your server, your data, under your control
DeepSeek-R1-Distill-Qwen-14B is a dense, open-source large language model distilled from DeepSeek-R1, a model developed as part of DeepSeek-AI’s first-generation reasoning suite. Centered on advanced reasoning, mathematical problem solving, and code generation, DeepSeek-R1-Distill-Qwen-14B leverages the Qwen2.5-14B architecture and is fine-tuned on data derived from its parent Mixture-of-Experts model. The model's design and training aim to offer generalization capabilities in reasoning-heavy benchmarks across mathematics, programming, and general question answering.
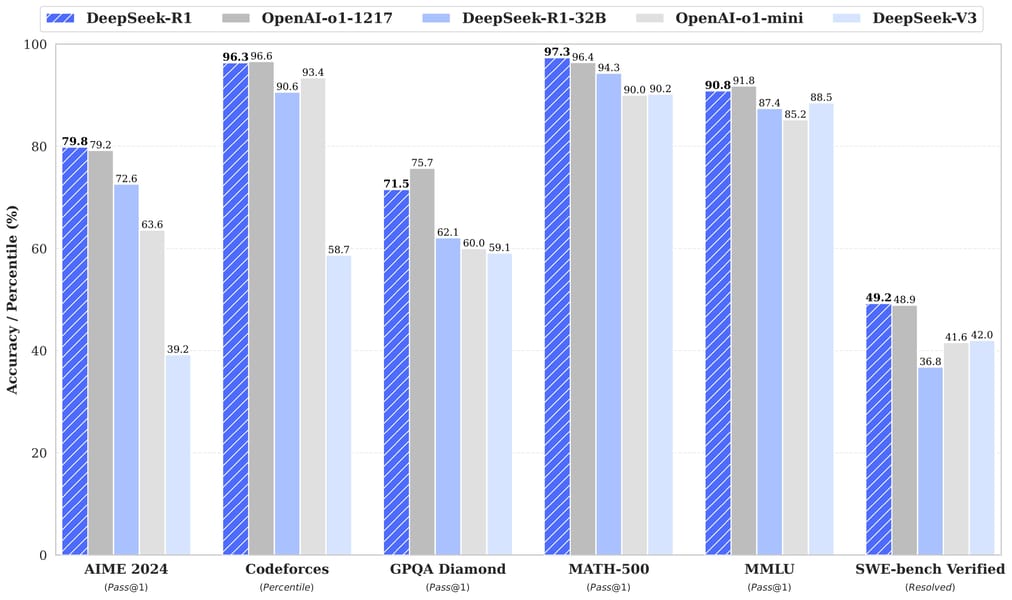
Benchmark performance comparison for DeepSeek-R1 and related models across multiple reasoning and code tasks. Data drawn from official DeepSeek-AI documentation.
DeepSeek-R1-Distill-Qwen-14B is founded on the Qwen2.5-14B transformer architecture and employs a distillation strategy in which its training data and reasoning objectives originate from DeepSeek-R1, a Mixture-of-Experts model comprising 671 billion parameters with 37 billion active per inference. Unlike its parent, the distilled series consists of dense models—structures that, while more compact, preserve reasoning ability through targeted fine-tuning.
The distillation methodology involves supervised fine-tuning on curated reasoning outputs from DeepSeek-R1 rather than applying reinforcement learning directly to the smaller model. Modifications were made to tokenization and configuration to facilitate effective transfer from the more complex parent model, producing a language model optimized for mathematical, logical, and programming-related tasks. The process is detailed extensively in the DeepSeek-R1 research paper.
Training Data and Fine-Tuning
DeepSeek-R1-Distill-Qwen-14B’s capabilities are largely defined by approximately 800,000 training samples assembled via DeepSeek-R1’s outputs. The dataset prioritizes complex reasoning, math, and logic problems, collected using rejection sampling from DeepSeek-R1's converged reinforcement learning checkpoints. Rule-based rewards and a generative reward model (DeepSeek-V3) are utilized to ensure that only high-quality chain-of-thought samples are used, filtering out mixed-language, unstructured, or redundant content.
Alongside reasoning-specific data, the training corpus includes roughly 200,000 non-reasoning samples. These address tasks such as narrative writing, factual question answering, translation, and self-cognition, often leveraging content from the DeepSeek-V3 supervised fine-tuning dataset. Select non-reasoning prompts are enriched with generated step-by-step explanations to foster more robust reasoning patterns. Notably, DeepSeek-R1-Distill models are trained solely via supervised fine-tuning, foregoing reinforcement learning at this stage.
Performance and Benchmark Evaluation
A significant focus of DeepSeek-R1-Distill-Qwen-14B is benchmarking against standardized reasoning and coding assessments. Noteworthy results, as reported in official DeepSeek releases, include a 69.7% pass rate on AIME 2024 (Pass@1), 93.9% on MATH-500 (Pass@1), and a Codeforces rating of 1481. The model also achieves 53.1% on LiveCodeBench, 80.0% for AIME 2024 (Consensus@64), and competitive scores on GPQA Diamond (59.1% Pass@1).
When contrasted with other models—such as QwQ-32B-Preview and GPT-4o-0513—DeepSeek-R1-Distill-Qwen-14B consistently demonstrates higher accuracy across all evaluation metrics. The accompanying benchmark chart provides a comprehensive view of these results and situates the model as a strong open competitor in specialized reasoning domains.
Applications and Usage
With high performance in reasoning-centric evaluations, DeepSeek-R1-Distill-Qwen-14B is suited for complex problem-solving scenarios, including mathematical analysis, automated code generation, logical deduction, and advanced general knowledge tasks. The model is particularly adept at tasks where step-by-step reasoning or chain-of-thought processes are required, such as mathematical derivations or resolving intricate programming queries.
Best practices for deployment suggest a temperature setting between 0.5 and 0.7 (optimally 0.6) to minimize incoherent outputs or repetitive behavior. Users are advised to integrate instructions, including formatting guidance, directly within the prompt rather than using a separate system prompt. To encourage structured reasoning, appending “<think>\n” at the start of the prompt and specifying final answer formatting—such as placing solutions within \boxed{}—have been shown to further enhance output quality. Few-shot prompting can degrade performance; a zero-shot approach with unambiguous prompts is recommended for best results.
Distinct from the distilled series are DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning without any supervised fine-tuning, and DeepSeek-R1, which builds on cold-start data followed by targeted reinforcement learning. Both models emphasize reasoning and logic but can exhibit issues such as language mixing and, in some settings, reluctance on factual queries after safety alignment.
Limitations and Licensing
Despite robust reasoning capacity, DeepSeek-R1-Distill-Qwen-14B currently lacks direct support in the popular Transformers library. Its output quality can be sensitive to prompt phrasing, with degraded performance seen in few-shot contexts or when prompts are unclear. The model primarily targets Chinese and English tasks; queries in other languages may prompt it to revert to English for reasoning steps, given its training emphasis.
Furthermore, as of its release, the model's performance in certain software engineering and factual domains (notably under heavy safety and factuality constraints) is an area of ongoing improvement.
DeepSeek-R1-Distill-Qwen-14B is made available under the MIT License, enabling commercial use, modifications, and derivative work—including training further large language models via distillation. The base Qwen2.5 series is distributed under the Apache 2.0 License, and full details on licensing can be found within the DeepSeek open-source repositories.