Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek R1 Distill Llama 70B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek R1 Distill Llama 70B
DeepSeek R1 Distill Llama 70B is a 70.6 billion parameter language model created through knowledge distillation from the larger DeepSeek-R1 model, using Llama 3.3 70B as its base architecture. The model specializes in reasoning tasks, achieving strong performance on mathematical and coding benchmarks including 70.0% on AIME 2024 and 94.5% on MATH-500, while being distributed under open source licensing for research and commercial use.
Explore the Future of AI
Your server, your data, under your control
DeepSeek-R1-Distill-Llama-70B is a dense large language model (LLM) resulting from the distillation of DeepSeek-R1, a generative AI system developed by DeepSeek-AI. Designed to enhance reasoning abilities within large language models, DeepSeek-R1-Distill-Llama-70B transfers advanced reasoning patterns from its parent model into a more accessible architecture. Built on Llama 3.3 70B as its base, the model is distributed under an open license conducive to both research and commercial utilization, and is part of an extensive family of reasoning-focused models supported by comprehensive reinforcement learning methodologies.
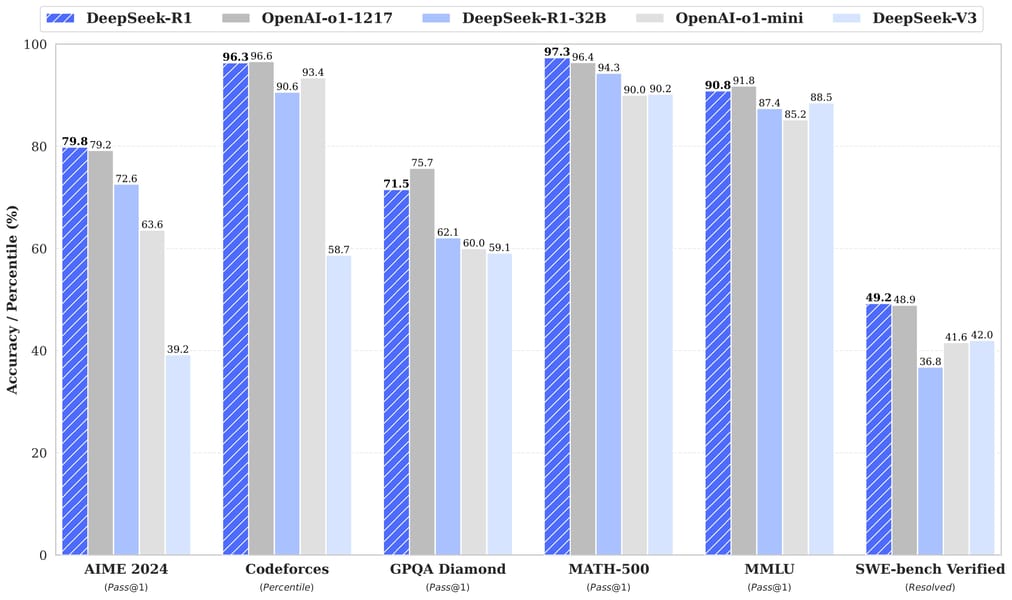
Bar chart presenting comparative benchmark scores for DeepSeek and OpenAI models across AIME 2024, Codeforces, GPQA Diamond, MATH-500, MMLU, and SWE-bench Verified tasks.
DeepSeek-R1-Distill-Llama-70B employs the Llama 3.3 70B architecture as its foundation, resulting in an overall parameter count of approximately 70.6 billion. The distillation is carried out using a large dataset generated by the larger DeepSeek-R1 model. This process selectively transfers the reasoning competencies learned by DeepSeek-R1, enabling the distilled model to retain high performance in key reasoning benchmarks while reducing model size and computational requirements. The resulting dense model thus inherits advanced reasoning abilities established through DeepSeek-R1's multi-stage training pipeline, and supports commercial applications through the permissive terms of its licensing.
Distillation in this context leverages supervised fine-tuning, using nearly 800,000 annotated samples generated by DeepSeek-R1 itself. These samples are tailored to capture reasoning-centric behaviors without the need for an additional reinforcement learning stage in the distilled models, illustrating the characteristics of the distillation methodology as detailed by DeepSeek-AI’s technical report.
Training Data and Methodology
The training procedure for DeepSeek-R1 and its distilled derivatives is characterized by a specific combination of supervised and reinforcement learning. DeepSeek-R1, the model providing training signals for distillation, is developed through a multi-stage pipeline that includes cold-start supervised fine-tuning with high-quality chain-of-thought data, iterative reasoning-oriented reinforcement learning, and further refinement via additional reinforcement and supervised stages.
To address initial performance and alignment with human reasoning, so-called "cold-start" data is collected through few-shot prompting, reflection-based generation, and human annotation. This cold-start foundation is subsequently enhanced using Group Relative Policy Optimization (GRPO), targeting tasks such as mathematics, code, logic, and scientific reasoning. An emphasis on language consistency rewards minimizes language mixing, particularly when operating in both Chinese and English.
For the distilled models—including DeepSeek-R1-Distill-Llama-70B—fine-tuning is performed directly on samples generated by the DeepSeek-R1 model, with the process omitting any additional reinforcement learning stage. This direct approach demonstrates that the distilled model can inherit strong reasoning performance efficiently by replicating the inference patterns of its larger ancestor, as described in the DeepSeek-R1 documentation.
Benchmark Performance and Comparative Evaluation
DeepSeek-R1-Distill-Llama-70B has been extensively evaluated on a variety of benchmarks relevant to reasoning, mathematics, and coding. Typical evaluation settings utilize a maximum context length of 32,768 tokens, a sampling temperature of 0.6, a top-p value of 0.95, and 64 completions per query to ascertain results in accordance with standard practices.
On the AIME 2024 (pass@1) benchmark, the model achieves a score of 70.0%, which is considerably higher than contemporary models such as GPT-4o-0513 (9.3%) and Claude-3.5-Sonnet-1022 (16.0%), and is comparable to OpenAI's o1-mini (63.6%). The model also demonstrates robust capability on MATH-500 (pass@1) with a score of 94.5%, outperforming other leading models, and attains 65.2% on the GPQA Diamond benchmark. For code generation and programming, the model achieves a pass@1 accuracy of 57.5% on LiveCodeBench and a CodeForces simulated rating of 1633.
As illustrated in comparative analyses—such as those presented in DeepSeek's technical benchmarks—these results position DeepSeek-R1-Distill-Llama-70B as an effective model for reasoning-centric tasks within its parameter class.
Applications and Typical Use Cases
DeepSeek-R1-Distill-Llama-70B is engineered for applications necessitating advanced reasoning, including mathematical problem-solving, code synthesis, and complex question answering. Its proficiency on benchmarks like AIME, MATH-500, LiveCodeBench, and CodeForces substantiates its utility in educational, research, and technical domains where logic, computation, and stepwise deduction are paramount.
The model also demonstrates strong results in general instruction following tasks and open-domain question answering, performing competitively on established benchmarks such as MMLU, GPQA Diamond, and IF-Eval. This makes it suitable for roles as a conversational agent, educational assistant, or automated coding tutor, especially in scenarios that require transparent, step-by-step explanations. Specific prompting conventions—such as instructing the model to begin reasoning with a "<think>\n" token or requesting boxed answers for math tasks—further enhance task-specific reliability, as described in deployment recommendations by DeepSeek-AI.
Family of Models and Related Research Directions
The DeepSeek-R1-Distill series comprises six dense models, each distilled from DeepSeek-R1 and based on either Llama or Qwen architectures. These include variations designed for different model sizes and base architectures, such as DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Llama-8B, and DeepSeek-R1-Distill-Qwen-14B, among others. All are aimed at systematically transferring advanced reasoning competencies to more accessible and efficient LLMs. The broader DeepSeek model family includes DeepSeek-R1-Zero, which exemplifies a pure reinforcement learning approach to reasoning, and DeepSeek-R1, which incorporates both RL and SFT to balance reasoning with output readability.
Model comparisons—such as between DeepSeek-R1-Distill-Llama-70B and DeepSeek-R1-Distill-Qwen-32B—demonstrate nuanced strengths across benchmarks, with both delivering consistent performance on reasoning and coding tasks according to the evaluation results.
Limitations
Despite its capabilities, DeepSeek-R1-Distill-Llama-70B retains certain notable limitations. The model’s general-purpose abilities—such as function calling, advanced multi-turn conversation, and structured JSON generation—remain less mature than those found in models like DeepSeek-V3. While optimized primarily for Chinese and English, language mixing can occur when engaging with prompts in other languages, resulting in less consistent performance outside these primary domains.
Sensitivity to prompt engineering is also observed, with empirical results indicating that few-shot prompting diminishes accuracy; zero-shot settings yield optimal results. For software engineering tasks, the impact of reinforcement learning was limited by evaluation efficiency constraints, leading to less pronounced gains. In safety-related evaluations, especially under certain reinforcement learning regimes, the model may refuse to answer some queries, which can impact benchmark outcomes as detailed in the DeepSeek-R1 paper.
Licensing and Availability
DeepSeek-R1-Distill-Llama-70B is distributed under the MIT License, permitting commercial use, modification, and derivative works. Since this model is based on Llama 3.3 70B, it additionally adheres to the Llama 3.3 license. The model weights and the supporting code repository are publicly available for research and application development within the bounds of these licenses.