Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek R1 Distill Llama 8B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek R1 Distill Llama 8B
DeepSeek-R1-Distill-Llama-8B is an 8-billion-parameter language model developed by DeepSeek-AI through knowledge distillation from larger teacher models in the DeepSeek-R1 series. Built on the Llama-3.1-8B architecture, the model specializes in mathematical reasoning, code generation, and complex problem-solving tasks, achieving strong performance on benchmarks like AIME 2024 and MATH-500 while maintaining computational efficiency compared to its larger counterparts.
Explore the Future of AI
Your server, your data, under your control
DeepSeek-R1-Distill-Llama-8B is a generative language model within the DeepSeek-R1 series, developed by DeepSeek-AI as part of an initiative to advance reasoning capabilities in large language models through reinforcement learning and knowledge distillation. This model is a distilled, 8-billion-parameter variant, built to capture much of the reasoning power of its larger "teacher" models, while operating with the efficiency and accessibility of a smaller architecture. Its design centers on excelling at mathematical problem-solving, code generation, and general reasoning tasks, drawing both from innovations in training methodology and architectural adaptation of state-of-the-art base models.
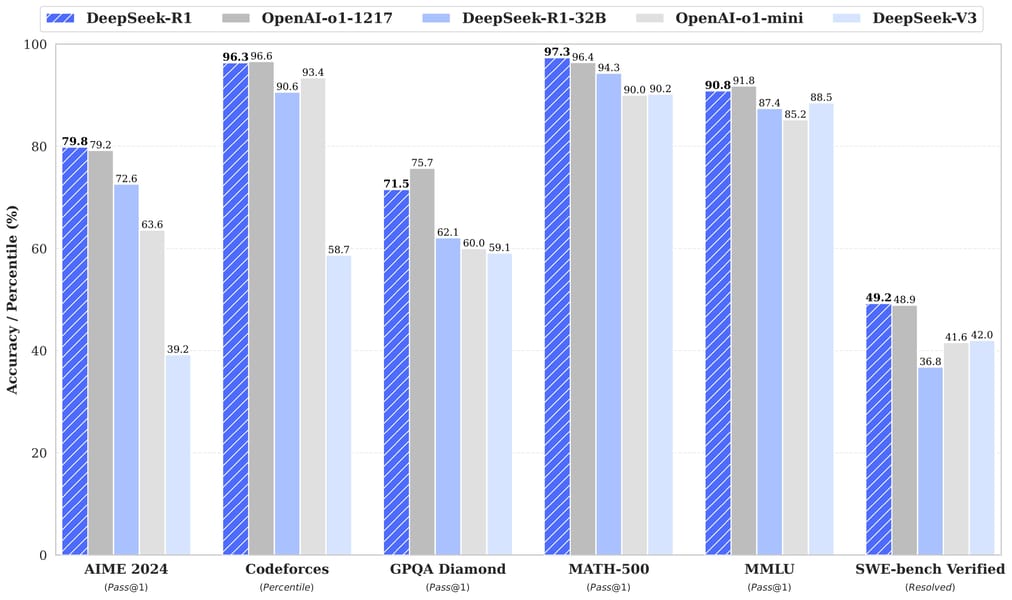
Benchmark comparison showing DeepSeek-R1's performance across several reasoning and coding tasks.
DeepSeek-R1-Distill-Llama-8B is constructed atop the Llama-3.1-8B architecture, a widely used open-source dense language model. The distillation process employs supervised fine-tuning, utilizing a large corpus of data generated by more advanced teacher models within the DeepSeek-R1 family. This approach enables the smaller, distilled model to inherit complex reasoning strategies identified by reinforcement learning conducted in larger models, reducing the need to apply computationally intensive RL directly to the base model.
The broader DeepSeek-R1 series features a hybrid design. The foundational DeepSeek-V3-Base, used for teacher models like DeepSeek-R1 and DeepSeek-R1-Zero, is a Mixture-of-Experts (MoE) model composed of 671 billion total parameters with 37 billion parameters activated per forward pass. The distilled models, such as DeepSeek-R1-Distill-Llama-8B, are dense and streamlined while still benefiting from the advanced alignment and reasoning developed in their larger counterparts. This design maximizes efficiency and model accessibility, making advanced reasoning functionality available in smaller deployments.
Training Methodology and Datasets
Training DeepSeek-R1-Distill-Llama-8B follows a multi-stage paradigm aimed at maximizing its reasoning and alignment capabilities. The initial training phases for the teacher models combine reinforcement learning (RL) and supervised fine-tuning (SFT) to foster sophisticated reasoning:
The teacher models leverage RL, particularly Group Relative Policy Optimization (GRPO), and incorporate a "cold-start" phase using thousands of complex Chain-of-Thought (CoT) examples, aligning the model's outputs with human preferences and accuracy criteria.
After RL convergence, rejection sampling is used to collect high-quality reasoning trajectories, which are combined with non-reasoning data in supervised fine-tuning.
A second RL phase further sharpens helpfulness and harmlessness while refining the model's command of step-by-step reasoning.
For the distillation stage, DeepSeek-R1-Distill-Llama-8B is fine-tuned on approximately 800,000 samples generated by the teacher models, focusing heavily on mathematical reasoning, code generation, and complex query resolution, as detailed in the research paper DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. This method enables the transfer of advanced problem-solving faculties to the distilled models without direct RL training on the smaller architectures, preserving much of the reasoning prowess of the teacher models.
These scores enable comparison against other compact and larger-scale language models. The model's distillation approach facilitates its performance on reasoning-intensive tasks, including those not specifically optimized for reasoning, while maintaining a compact parameter count.
Model Family and Comparisons
The DeepSeek-R1 series spans several models, each engineered to showcase different balances of size, speed, and reasoning capacity. The flagship models—DeepSeek-R1 and DeepSeek-R1-Zero—utilize Mixture-of-Experts architectures and extensive RL training. DeepSeek-R1-Zero, in particular, employs RL from scratch, while DeepSeek-R1 incorporates low-shot Chain-of-Thought seeds before RL for improved language consistency.
Within the distillation family, DeepSeek-R1-Distill-Llama-8B is one of several dense variants derived from open-source bases, including Qwen and Llama models. Larger siblings, such as DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Llama-70B, have demonstrated competitive performance among dense models on selected reasoning benchmarks. The range of distilled models illustrates that much of the advanced reasoning attributed to large, specialized models can persist in smaller, efficient derivations, as observed in public evaluations and comparisons with other contemporary language models.
Limitations and Known Shortcomings
Despite its focused training, DeepSeek-R1-Distill-Llama-8B presents limitations common to models specialized in reasoning. The model displays sensitivity to prompt formulation—few-shot prompting may degrade accuracy, and zero-shot prompting is generally recommended. While measures to mitigate language mixing and readability have been integrated into upstream training, issues may occasionally surface when queries are not in English or Chinese. In broader language tasks like function calling, extended dialogue, role-playing, or precise JSON formatting, the model may trail behind generalist architectures. Its improvements in software engineering benchmarks are restrained by the computational intensity of these evaluations.
Licensing and Usage
The code and model weights for DeepSeek-R1-Distill-Llama-8B are distributed under the MIT License, permitting broad use, modification, and derivative works, including further distillation. The model is derived from Llama-3.1-8B, carrying with it obligations under the Llama licensing terms. These provisions endorse openness and scientific reuse, encouraging further research and application while adhering to relevant copyright requirements.