Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek R1 Distill Qwen 32B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek R1 Distill Qwen 32B
DeepSeek R1 Distill Qwen 32B is a text generation model developed by DeepSeek-AI through knowledge distillation from the larger DeepSeek-R1 teacher model. Built on the Qwen2.5-32B architecture, it utilizes reinforcement learning and distillation techniques to enhance reasoning capabilities across mathematical problems, code generation, and cognitive tasks, demonstrating strong performance on benchmarks like AIME 2024 and MATH-500.
Explore the Future of AI
Your server, your data, under your control
DeepSeek R1 Distill Qwen 32B is a generative artificial intelligence model developed by DeepSeek-AI. Positioned within the DeepSeek-R1 model series, this model emphasizes enhanced reasoning capabilities, harnessing advanced reinforcement learning (RL) and knowledge distillation strategies. Built upon the Qwen2.5-32B base model, DeepSeek R1 Distill Qwen 32B is designed to excel at mathematical reasoning, code generation, and general cognitive tasks. The distillation process transfers reasoning patterns from the larger DeepSeek-R1 teacher model, yielding a dense, efficient system suitable for broad research and application contexts.
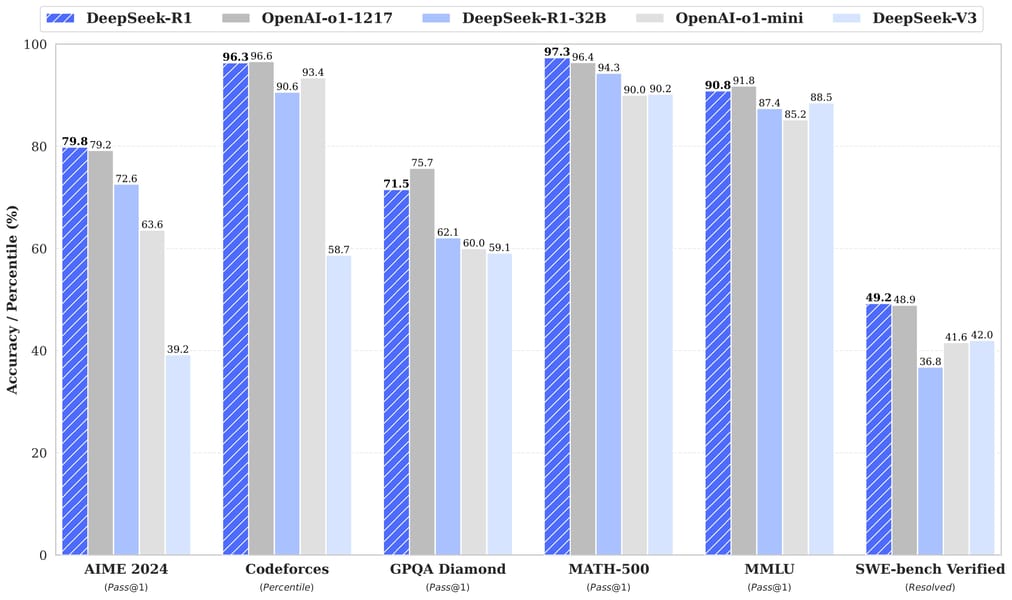
Benchmark comparison between DeepSeek-R1 models and peer systems across tasks such as AIME 2024, Codeforces, GPQA Diamond, and MATH-500, highlighting the model's relative accuracy and percentile performance.
DeepSeek R1 Distill Qwen 32B inherits its dense architecture from Qwen2.5-32B, further refined through a targeted distillation strategy. The teacher model, DeepSeek-R1, is a Mixture-of-Experts (MoE) language model based on the DeepSeek-V3-Base architecture. DeepSeek-R1 features 671 billion total parameters, with 37 billion activated per forward pass.
The development of DeepSeek-R1 and its distilled derivatives leverages a two-tiered RL methodology: an initial RL stage to establish complex reasoning behaviors, and a subsequent RL phase to align outputs with human preferences of helpfulness and harmlessness. Prior to these RL stages, supervised fine-tuning (SFT) is employed to "seed" basic reasoning and general language skills. The distillation step for models such as DeepSeek R1 Distill Qwen 32B uses approximately 800,000 curated samples generated by the DeepSeek-R1 teacher, fine-tuning the target model for advanced reasoning performance.
Data Sources and Training Methodology
Training data for DeepSeek R1 Distill Qwen 32B is generated via the DeepSeek-R1 model and comprises two principal categories. The first and largest portion consists of around 600,000 samples oriented toward reasoning-intensive challenges—such as mathematics, coding, science, and logic—curated using rule-based and generative reward mechanisms. The second portion includes approximately 200,000 general-purpose samples, covering writing, factual question answering, translation, and self-cognition, with a subset explicitly leveraging Chain-of-Thought (CoT) reasoning.
The upstream DeepSeek-R1 teacher model is trained via a staged process. It begins with DeepSeek-R1-Zero, which employs RL using Group Relative Policy Optimization (GRPO) without any initial SFT. This yields emergent reasoning capabilities but introduces challenges, such as repetition and mixed-language responses. The subsequent DeepSeek-R1 stage improves on this by pre-conditioning with a small volume of carefully-selected CoT data ("cold start"), enhancing readability and language consistency. The final distilled datasets, produced after RL convergence, are curated with rejection sampling and SFT to exclude undesirable attributes (e.g., mixed language or excessive length), ensuring high-quality training inputs for downstream distillation, as detailed in the DeepSeek-R1 research paper.
Performance and Benchmark Evaluation
DeepSeek R1 Distill Qwen 32B demonstrates robust performance on a diverse set of evaluation benchmarks in mathematical reasoning, code generation, and general knowledge tasks. On tasks like AIME 2024, MATH-500, and LiveCodeBench, it outperforms several competing dense models and closely follows or, in some cases, surpasses models that are considerably larger or trained with different methodologies.
Across key benchmarks, DeepSeek R1 Distill Qwen 32B has been shown to:
Achieve a Pass@1 score of 72.6 on AIME 2024, outperforming both QwQ-32B-Preview and o1-mini.
Reach a Pass@1 of 94.3 on MATH-500 and 57.2 on LiveCodeBench, reflecting strong mathematical and coding abilities.
Excel on GPQA Diamond and Codeforces, ranking among the top performers for general knowledge and programming competition proficiency.
The performance gains observed with DeepSeek R1 Distill Qwen 32B are attributed to its distillation from the large-scale RL-trained DeepSeek-R1 model, rather than relying solely on direct RL training at the smaller scale. This approach enables efficient transfer of the teacher model's reasoning strategies into a more compact and versatile system, as highlighted across multiple technical reports and benchmarks.
Applications and Use Cases
DeepSeek R1 Distill Qwen 32B is particularly well-suited for scenarios demanding intricate reasoning, robust problem-solving, and high-level cognitive tasks. Typical applications include advanced mathematics problem solving (as evaluated by AIME and MATH-500 benchmarks), code synthesis and debugging (as reflected in LiveCodeBench and Codeforces performance), and general knowledge reasoning (as assessed by GPQA Diamond).
Given its proficiency in Chain-of-Thought style tasks, the model finds further application in question answering, technical and scientific writing, summarization, and scenarios where explanations and stepwise logic are critical. The broader DeepSeek-R1 family, from which this model is derived, is also used for creative writing, editing, and tasks requiring extended context handling, as described in the DeepSeek-R1 research documentation.
Limitations
While DeepSeek R1 Distill Qwen 32B demonstrates substantial capabilities, certain limitations are documented. The model is optimized for Chinese and English, which can result in language mixing or reduced performance when queried in other languages. Its outputs are prompt-sensitive, and few-shot prompts may lead to diminished reasoning ability; zero-shot querying is generally recommended. The model performs best when instructions are provided directly in the user prompt, without using a separate system prompt.
In comparison to earlier models such as DeepSeek-V3, DeepSeek-R1 derivatives may be less capable in some complex structured tasks, including function calling or multi-turn dialogues. Additionally, in domain-specific software engineering benchmarks, improvements over previous generations are limited by the current scope of RL training data.
Licensing
DeepSeek R1 Distill Qwen 32B is released under the MIT License, which grants broad rights for use, modification, and distribution, including in commercial settings. The underlying Qwen2.5-32B base model is distributed under the Apache 2.0 License, and users should be mindful of corresponding terms and attribution requirements. Models distilled from Llama series inherit their respective Llama-3.1 or Llama-3.3 licenses.