Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek R1 Distill Qwen 1.5B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek R1 Distill Qwen 1.5B
DeepSeek R1 Distill Qwen 1.5B is a compact text generation model developed by Deepseek AI through distillation from the larger DeepSeek-R1 reasoning model. Built on the Qwen2.5-Math-1.5B architecture, it transfers chain-of-thought reasoning capabilities to a smaller format via supervised fine-tuning on 800,000 samples. The model specializes in mathematical problem-solving and logical reasoning tasks.
Explore the Future of AI
Your server, your data, under your control
DeepSeek-R1 Distill Qwen 1.5B is a compact large language model (LLM) developed by DeepSeek-AI, constituting one of the six "distilled" variants derived from the larger DeepSeek-R1 reasoning models. Designed to make chain-of-thought reasoning available in resource-constrained settings, DeepSeek-R1 Distill Qwen 1.5B leverages a distillation process that transfers capabilities from larger reinforcement learning (RL)-trained models into a smaller, efficient architecture. This model is focused on mathematical problem-solving, logical reasoning, and code understanding, while considering performance and efficiency for research applications.
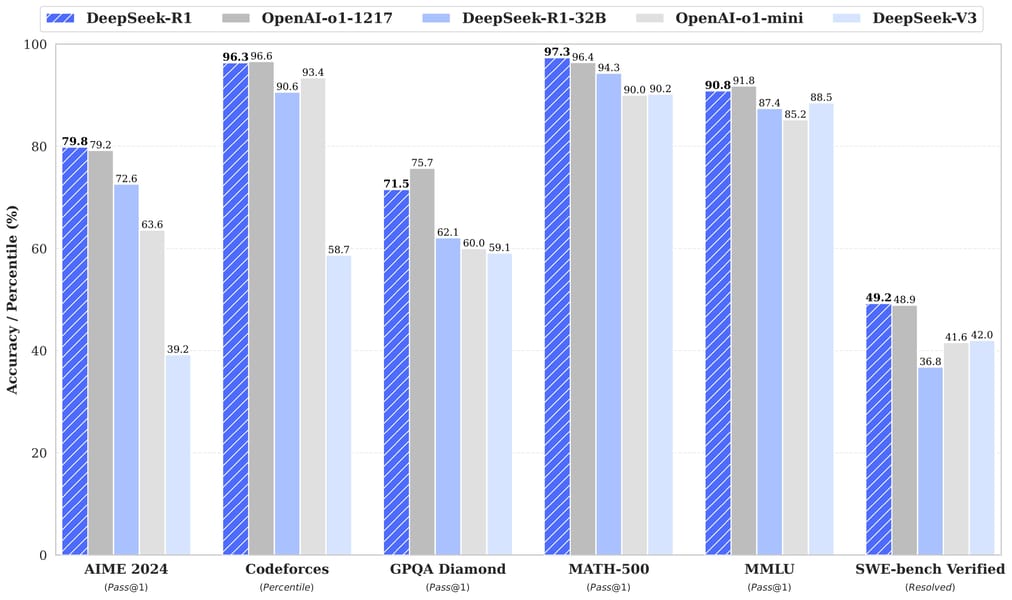
Benchmark performance comparison: DeepSeek-R1 series models versus OpenAI and DeepSeek-V3 baselines, evaluated on mathematics, coding, and general reasoning tasks.
DeepSeek-R1 Distill Qwen 1.5B is constructed using the Qwen2.5-Math-1.5B base architecture, a transformer-based LLM tailored for mathematical and logical reasoning. The distillation process involves supervised fine-tuning (SFT) on a curated dataset generated by the parent DeepSeek-R1 model. Unlike standard SFT, distillation targets the transfer of specific reasoning patterns—such as self-verification, reflection, and extended chain-of-thought (CoT) generation—from the large RL-trained model to the smaller student model. DeepSeek-R1, the teacher model, itself is based on DeepSeek-V3-Base, which utilizes a Mixture-of-Experts (MoE) framework and was trained with 671 billion total parameters and 37 billion activated parameters, resulting in reasoning abilities refined by large-scale reinforcement learning.
The distillation to Qwen 1.5B uses approximately 800,000 training samples synthesized by DeepSeek-R1, encompassing domains including mathematics, programming, factual question answering, translation, and self-cognition. This dataset is curated through rejection sampling to ensure the student model is exposed to high-quality reasoning trajectories. Notably, the distillation excludes an additional RL-finetuning stage, focusing on supervised learning to demonstrate the efficacy of reasoning transfer via distillation alone, as detailed in the DeepSeek-R1 technical report.
Training Data and Methodological Innovations
The DeepSeek-R1 Distill Qwen 1.5B model is uniquely trained on data curated by the DeepSeek-R1 parent model, itself a product of two RL and two SFT training phases. The 800,000-sample dataset used for fine-tuning the Qwen 1.5B distillation includes diverse problem types but with a specialized emphasis on reasoning, especially in mathematics and programming. The original DeepSeek-R1 series leverages both large-scale RL and traditional SFT, aiming to develop complex reasoning patterns aligned with human preferences.
Rejection sampling is employed to select high-quality reasoning outputs from DeepSeek-R1. This methodology ensures that the distilled Qwen 1.5B model internalizes not only domain knowledge, but also problem-solving strategies developed by its larger predecessor. The base data foundation, the DeepSeek-V3 dataset, further contributes non-reasoning information, broadening the utility of the distill models beyond mathematics to domains such as factual knowledge and language translation. More information on the data pipeline and methodology can be found in the DeepSeek-R1 repository.
Performance and Benchmark Evaluation
DeepSeek-R1 Distill Qwen 1.5B exhibits performance for its scale across several standardized reasoning and coding benchmarks, particularly in mathematics. Evaluation protocols typically employ up to 32,768 token maximum sequence lengths and sampling parameters of a 0.6 temperature and 0.95 top-p, with outputs for each query estimated over 64 response samples to measure pass@1. These rigorous evaluations confirm the model's ability to transfer chain-of-thought capabilities from its larger teacher.
On the AIME 2024 mathematics benchmark, DeepSeek-R1 Distill Qwen 1.5B achieves a pass@1 accuracy of 28.9% and a consistency-at-64 accuracy of 52.7%. On MATH-500, a challenging mathematical reasoning test, the model attains a pass@1 score of 83.9%. It also demonstrates notable results on GPQA Diamond (pass@1: 33.8%), LiveCodeBench for coding (pass@1: 16.9%), and a Codeforces rating of 954. When compared with similar-scale non-reasoning models, DeepSeek-R1 Distill Qwen 1.5B outperforms baselines such as GPT-4o-0513 and Claude-3.5-Sonnet-1022 on several mathematical benchmarks, indicating effective transfer of reasoning abilities. Comparative benchmark analyses, including broader DeepSeek models, are available in the DeepSeek-R1 paper.
Applications and Use Cases
The primary use case for DeepSeek-R1 Distill Qwen 1.5B centers on tasks that demand reasoning, particularly in mathematics, algorithmic problem-solving, and single-turn coding tasks. The reduced size of the model makes it viable for deployment in research environments and applications where memory or compute limitations are a concern. While it does not reach the full capabilities of its DeepSeek-R1 or DeepSeek-V3 parent models in multi-turn conversations, function calling, or contextually complex tasks, it performs efficiently in streamlined problem-solving and inference settings.
Recommended usage practices include avoiding system prompts (providing all instructions in the user prompt directly) and, for mathematical queries, explicitly instructing the model to reason step-by-step and format final answers within notation such as “\boxed{}.” Instructing the model to begin responses with a marker like "<think>\n" can further encourage explicit chain-of-thought reasoning. Guidance on evaluation and interface support is elaborated in the DeepSeek-R1 documentation.
Limitations
Despite its strengths, DeepSeek-R1 Distill Qwen 1.5B exhibits limitations typical of distilled small models. Chief among these is sensitivity to prompt phrasing: zero-shot, clearly specified problems yield the best results, while few-shot prompts or ambiguous queries can degrade performance. The model may exhibit "language mixing"—preferring English for reasoning even when questions are asked in other languages—since it is primarily optimized for English and Chinese. In broader tasks such as function calling, multi-turn dialogues, or advanced software engineering use cases, the model generally lags behind larger-scale models in the DeepSeek family, as noted in DeepSeek-R1's benchmark summary and related discussion.
Licensing and Model Family
The codebase and weights for DeepSeek-R1 Distill Qwen 1.5B are released under the MIT License, permitting broad commercial and research use, as well as modification and further distillation. It is important to note that the underlying Qwen2.5-Math-1.5B base model is licensed under Apache 2.0, thus users should be mindful of license compatibility in downstream applications.
DeepSeek-R1 Distill Qwen 1.5B is part of a broader family of distilled models, including Qwen-7B, Qwen-14B, Qwen-32B, Llama-8B, and Llama-70B-Instruct variants. Each model is tailored to condense DeepSeek-R1’s reasoning capabilities into architectures fitting various operational scales, described extensively on the DeepSeek-AI GitHub.