Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek R1 Distill Qwen 7B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek R1 Distill Qwen 7B
DeepSeek R1 Distill Qwen 7B is a 7.62 billion parameter language model developed by DeepSeek-AI through knowledge distillation from the larger DeepSeek-R1 system. Built on the Qwen2.5-Math-7B architecture, it specializes in mathematical reasoning, logical analysis, and code generation tasks, achieving competitive performance on benchmarks like AIME 2024 and MATH-500 while supporting long-form reasoning up to 32,768 tokens.
Explore the Future of AI
Your server, your data, under your control
DeepSeek R1 Distill Qwen 7B is a dense, distilled generative AI language model developed by DeepSeek-AI, designed to deliver robust reasoning capabilities in a compact and efficient format. As one of six models derived from the DeepSeek-R1 family, its architecture is based on the Qwen2.5-Math-7B model, integrating reasoning proficiency inherited from the much larger DeepSeek-R1 system. This model is particularly oriented toward tasks requiring mathematical, logical, and coding-based reasoning.
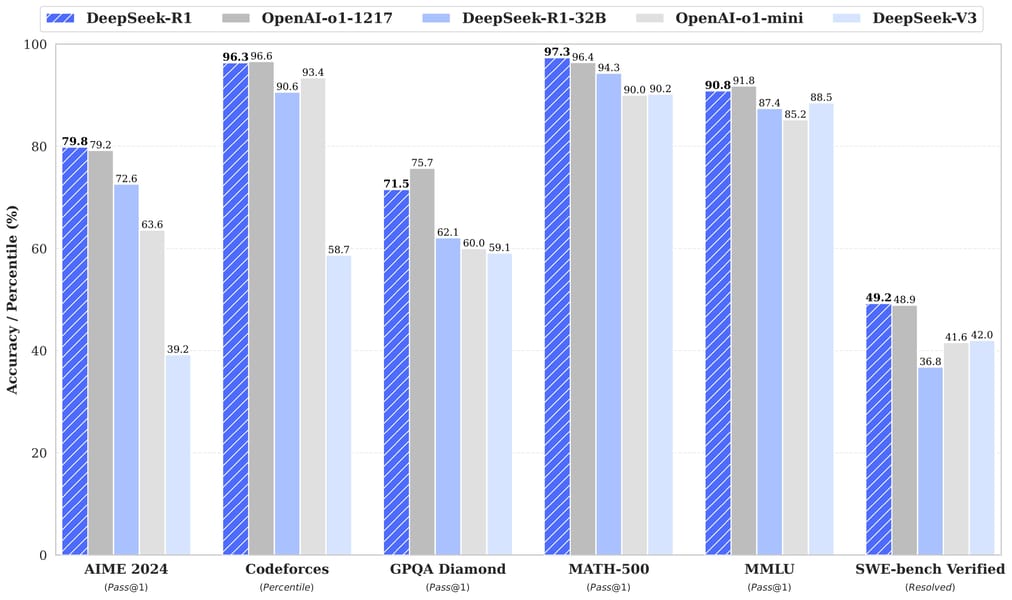
Bar chart illustrating comparative benchmark performance for DeepSeek-R1, OpenAI-01-1217, DeepSeek-R1-32B, OpenAI-01-mini, and DeepSeek-V3 across six evaluation tasks. Higher scores represent greater accuracy or percentile rankings on tasks including mathematics and reasoning.
DeepSeek R1 Distill Qwen 7B is constructed upon the Qwen2.5-Math-7B architecture, integrating 7.62 billion activated parameters. Its training pipeline emphasizes distillation, a process by which the knowledge and reasoning behaviors from the larger DeepSeek-R1 teacher model are transferred into the smaller student models. This approach enables DeepSeek R1 Distill Qwen 7B to effectively replicate the advanced reasoning patterns of its teacher, outperforming similarly sized models trained directly via reinforcement learning.
The distillation process employed approximately 800,000 curated samples generated by DeepSeek-R1, of which around 600,000 are focused on reasoning and 200,000 are non-reasoning samples. Training is performed via supervised fine-tuning (SFT), utilizing outputs from DeepSeek-R1 as targets. In contrast to its teacher, which employs a multi-stage reinforcement learning (RL) and SFT pipeline with rule-based and language consistency-based reward modeling, the distilled models such as DeepSeek R1 Distill Qwen 7B rely solely on SFT. This distinction highlights a difference in training methodology.
A defining feature of this model is its support for long-form reasoning: the maximum generation length is set at 32,768 tokens, aligning with the other members of the DeepSeek-R1 series and thus enabling extended multi-step problem solving.
Reasoning Capabilities and Benchmark Performance
The DeepSeek R1 Distill Qwen 7B model has demonstrated competitive results across a variety of standardized reasoning benchmarks, particularly in mathematics and code generation. For example, on the AIME 2024 benchmark, it achieves a pass@1 score of 55.5% and a cons@64 score of 83.3%. On MATH-500, the model reports a pass@1 rate of 92.8%, outperforming non-reasoning models and approaching larger, more resource-intensive systems.
Relative to other models, DeepSeek R1 Distill Qwen 7B distinguishes itself by surpassing GPT-4o-0513 and Claude-3.5-Sonnet-1022 in mathematics-focused tasks under the same pass@1 metric. Furthermore, on the GPQA Diamond reasoning test, the model attains 49.1% pass@1, and on LiveCodeBench, it reaches 37.6% pass@1. The Codeforces Rating for the model is reported at 1189, indicating capable performance on competitive programming tasks.
Performance across these diverse tasks is visualized in bar charts such as the one provided above, which highlight the comparative strengths of DeepSeek models versus prominent contemporary alternatives.
Core Features and Usage
Key to DeepSeek R1 Distill Qwen 7B’s effectiveness is its ability to produce detailed chain-of-thought (CoT) responses, attributed to the reasoning-oriented knowledge distilled from DeepSeek-R1. The reasoning process involves generating multi-step explanations, self-verification, and explicit answer boxing, which are especially advantageous in highly structured problem domains.
The model is primarily suited to applications requiring mathematically rigorous analysis, formal logic, scientific reasoning, and program synthesis. The distilled approach supports efficient inference and lower resource requirements while retaining core reasoning competence—key for research, education, or engineering domains where computational overhead is a concern.
To maximize reasoning performance, users are encouraged to prompt the model with explicit instructions, such as including “Please reason step by step, and put your final answer within \boxed{}.” For optimal output quality, recommended generation parameters include a temperature between 0.5 and 0.7 (with 0.6 as default), and a top-P value of 0.95. Zero-shot prompting is favored over few-shot templates, as the former has been shown to yield more reliable results.
Model Family, Limitations, and Licensing
DeepSeek R1 Distill Qwen 7B is part of a broader suite of distilled models within the DeepSeek-R1 family, which includes variants based on both Qwen2.5 and Llama architectures and ranging from 1.5B to 70B parameters. These models exploit the distillation methodology to encapsulate advanced reasoning into more manageable model sizes.
Nevertheless, the DeepSeek-R1 series, including the distill variants, has some limitations. Issues noted include sensitivity to prompt phrasing, a tendency toward language mixing (especially outside Chinese and English), and less comprehensive support for features such as function calling and complex conversational flows, compared to more generalist large language models like DeepSeek-V3. The model family currently lacks direct, native support in mainstream libraries such as Hugging Face Transformers, though they mirror the general inference methods of Qwen and Llama-type models.
In terms of licensing, DeepSeek R1 Distill Qwen 7B is distributed under the MIT License, which permits broad use, modification, and commercial deployment. It is crucial to acknowledge that the base model, Qwen2.5-Math-7B, is initially licensed under Apache 2.0, and derivative models must comply with their respective upstream licenses. Release information and ongoing research development are detailed in the original paper, "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning".
Applications and Outlook
The capacity for in-depth stepwise reasoning makes DeepSeek R1 Distill Qwen 7B highly suitable for automated tutoring, solution verification in mathematics or software engineering, scientific research assistants, and environments where model transparency and intermediate thought processes are critical. Its design supports robust performance in answer consistency, logical deduction, and code correctness, offering an efficient alternative to much larger models for specialized reasoning applications.
As model development continues, further enhancements in multilingual ability, prompt robustness, and downstream support in widely used platforms are expected to broaden the usability of the DeepSeek-R1 Distill model family.