Launch a dedicated cloud GPU server running Laboratory OS to download and run Realistic Vision XL using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
SG_161222 / Realistic Vision XL
Realistic Vision XL is a photorealistic image generation model developed by SG_161222 through checkpoint merging of multiple Stable Diffusion XL-based models. Version 5.0, released in February 2024, specializes in generating high-quality human portraits with detailed facial anatomy and sophisticated lighting. The model supports high-resolution outputs and is distributed under the CreativeML Open RAIL++-M license.
Explore the Future of AI
Your server, your data, under your control
Realistic Vision XL (also referred to as RealVisXL) is a photorealistic generative AI model designed for high-quality image synthesis. Developed as a "checkpoint merge," Realistic Vision XL relies on the SDXL 1.0 base model, incorporating features and learned patterns from several other pre-trained models. This model is intended primarily for generating realistic images, with a focus on detailed human portraits and varied settings, offering advanced control and versatility for users who seek high-fidelity visual outputs.
Sample output from Realistic Vision XL: a detailed black and white portrait of a young woman produced by the model.
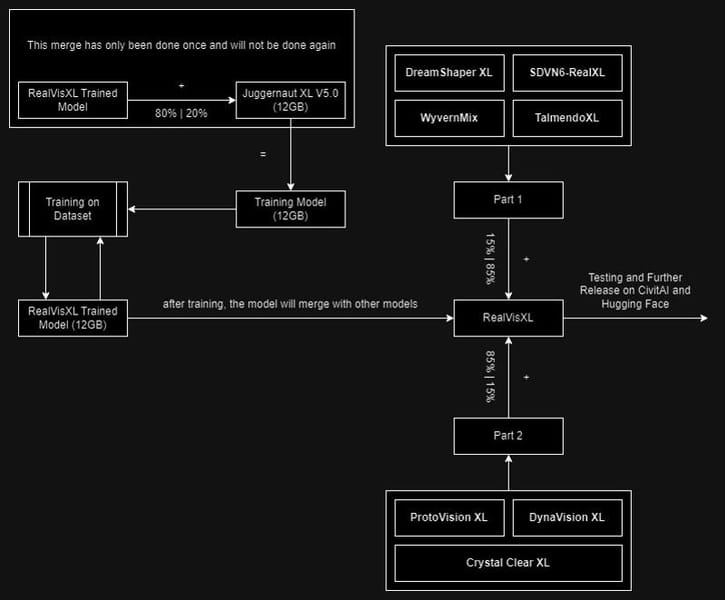
Realistic Vision XL was engineered through a process known as checkpoint merging, where weights from multiple specialized models are blended to inherit their strengths. The foundation is the SDXL 1.0 model, which serves as an advanced stable diffusion backbone for high-resolution image generation. Subsequent models, such as DreamShaper XL and Juggernaut XL, among others, are integrated at varied proportions, as illustrated in the model’s technical documentation and merging pipeline.
Diagram detailing the training, merging process, and release pipeline for Realistic Vision XL, indicating how various models contribute to the final model release.
The most recent major update, Version 5.0, was published in February 2024, after a training process involving 672,000 steps. The released model weights are distributed using SafeTensor format, offering improved compatibility and security for downstream applications, as outlined on the Civitai project page.
Capabilities and Features
Realistic Vision XL is optimized for producing photorealistic images, with special emphasis on accurate facial anatomy, intricate details, and sophisticated lighting scenarios. The model yields a broad range of realistic portraits for both women and men, with enhanced rendering of fine textures and natural dynamics of light and shadow. Improvements in Version 5.0 include finer anatomical accuracy and greater model robustness, as detailed in the model documentation on Hugging Face.
Example of advanced photorealistic lighting, facial detail, and shadow management in a male portrait, produced by Realistic Vision XL.
The model accommodates high-resolution outputs and offers settings for different trade-offs between speed and fidelity, such as the SDXL Lighting and SDXL Turbo sub-versions, which leverage lower sampling steps for rapid image synthesis.
Performance and Community Reception
Since its release, Realistic Vision XL V5.0 has attracted substantial user engagement and critical attention within the generative AI community. According to statistics from Civitai, the model has accumulated tens of thousands of downloads and thousands of favorable reviews, reflecting a broad and active user base. On Hugging Face, Realistic Vision XL ranked among the prominent community-source models by monthly download volume.
Performance metrics, while primarily community-driven via qualitative reviews and star ratings, emphasize the model's strength in portrait synthesis and photorealism. Users report that the model delivers outputs with high detail fidelity, making it suitable for use cases requiring lifelike imagery.
Model Usage and Technical Recommendations
To achieve optimal results, guidance on sampling strategies and parameter selection is provided in the official documentation. Recommended samplers include DPM++ SDE Karras and DPM++ 2M Karras, typically using 30 to 50 sampling steps for standard versions. For upscaling tasks, the model documentation suggests employing upscale factors between 1.1 and 1.5 and using recommended upscalers such as 4x-NMKD-Superscale-SP or 4x-UltraSharp to preserve clarity at larger resolutions.
Negative prompts, which guide the model away from undesired artifacts, are also specified: terms like "worst quality," "low quality," and "open mouth" can be used to suppress certain visual patterns. Detailed negative prompt recommendations can be found in the documentation on both Civitai and Hugging Face.
The model is released under the CreativeML Open RAIL++-M license, including an addendum describing permissible use and distribution.
Limitations and Known Issues
Despite its strengths, Realistic Vision XL presents certain limitations reported by users. Occasional output artifacts include blurred color regions or completely black images. Some users also observe challenges in replicating precise lighting conditions, with outputs sometimes displaying overexposed or heavily shadowed sections. There are user reports regarding a decline in variant consistency compared to earlier versions, particularly when attempting to recreate previous outputs using stored model metadata. These limitations are documented in the project’s issue threads and public reviews, as referenced on Civitai.
Related Models and Further Resources
The developer of Realistic Vision XL, SG_161222, has released several related models based on the SDXL framework, such as ParagonXL, NovaXL, and RealDreamXL, each catering to different aesthetic preferences or synthesis strategies. More information on these related models and updates can be found in the curated SG_161222 model collection.