Launch a dedicated cloud GPU server running Laboratory OS to download and run SDXL Lightning using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
ByteDance / SDXL Lightning
SDXL Lightning is a text-to-image diffusion model developed by ByteDance that uses progressive adversarial distillation to generate 1024×1024 pixel images in 1-8 inference steps. The model distills Stable Diffusion XL through a training process combining mean squared error loss and adversarial refinement, available in both LoRA and full UNet checkpoint formats for flexible integration.
Explore the Future of AI
Your server, your data, under your control
SDXL-Lightning is an open-source generative AI model developed by ByteDance for text-to-image synthesis. As an efficient distillation of Stable Diffusion XL, SDXL-Lightning leverages a progressive adversarial diffusion distillation process to enable rapid, high-resolution image generation—up to 1024×1024 pixels—with as few as one inference step. The model’s release includes both LoRA (Low-Rank Adaptation) and full UNet weights, offering options for integration.
Eight distinct, high-resolution images generated by SDXL-Lightning, highlighting the model's versatility in subject matter and visual style based on text prompts.
SDXL-Lightning is distilled from the SDXL Base 1.0 model, inheriting its latent diffusion framework and underlying UNet architecture. By operating in a compact latent space with a Variational Autoencoder (VAE), the model can efficiently encode and reconstruct high-resolution images while maintaining fidelity and diversity.
The progressive adversarial diffusion distillation method is a core component of SDXL-Lightning's design. Initially, the model is distilled using mean squared error (MSE) loss across many timesteps to ensure mode coverage. In subsequent stages, a discriminator—built upon the pre-trained SDXL UNet encoder and operating in latent space—enables adversarial training, enhancing realism and detail while reducing the inference step count. The process alternates between a conditional objective to preserve the generative path of the teacher model and an unconditional one to prioritize semantic correctness and reduce artifacts, such as erroneous feature blending.
This training protocol supports both LoRA and full UNet adaptations. LoRA checkpoints enable lightweight integration with other SDXL-based systems, while full UNet checkpoints maximize generation quality.
Technical Capabilities and Performance
SDXL-Lightning generates photorealistic images at 1024×1024 resolution in as few as 1, 2, 4, or 8 diffusion steps, compared to the dozens typically required by conventional diffusion models. This efficiency is achieved without substantial reduction in image fidelity or text alignment, supported by both quantitative and qualitative benchmarks in the official research paper.
Quantitative evaluations indicate that SDXL-Lightning demonstrates competitive performance compared to other open-source fast distillation models, such as SDXL-Turbo and LCM, in critical areas:
Fréchet Inception Distance (FID) for overall quality: SDXL-Lightning exhibits competitive FID-Whole values and favorable FID-Patch metrics that assess fine detail.
CLIP score for prompt-image alignment: The model maintains robust text-image correspondence across step counts.
Resolution and speed: Unlike SDXL-Turbo, which is limited to 512px outputs, SDXL-Lightning supports full 1024px generations while delivering images rapidly via fewer inference steps.
The architecture supports both classifier-free guidance (CFG) and unconditional generation. The model also demonstrates compatibility with ControlNet-like conditional guidance, allowing for user-driven constraints such as structural overlays (e.g., edges or depth maps), although minor degradation may occur under extreme fast-generation settings.
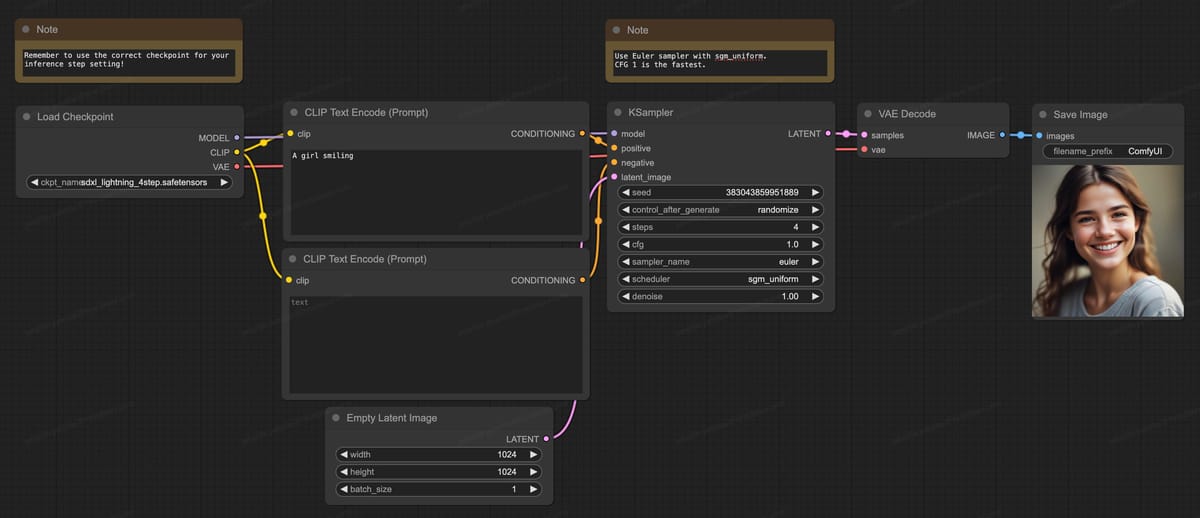
A complete ComfyUI workflow for SDXL-Lightning 4-step generation, including loading checkpoints, setting prompts, sampling, and the resulting high-resolution output for the prompt: 'A girl smiling'.
SDXL-Lightning’s distillation process utilizes large, high-quality datasets for data diversity and semantic richness. Images were selected from subsets of the LAION and COYO datasets, focusing on resolutions exceeding 1024px. To further refine the training corpus, LAION images were filtered for high aesthetic scores using an automated metric and for sharpness via a Laplacian filter; text prompt data were cleaned to ensure prompt-image alignment.
The training regime unfolds in multiple stages:
Initial MSE distillation reduces the teacher model’s inference steps from 128 to 32, with classifier-free guidance applied.
Progressive adversarial distillation then further reduces step count (32 → 8 → 4 → 2 → 1), alternating between conditional training for strict mode coverage and unconditional fine-tuning for improved semantic accuracy.
Both LoRA and full UNet models are trained at each stage, the former then merged for continued training to maximize compatibility.
The model demonstrates stability across timesteps, which is achieved partly by training on a mixture of noise levels and by tailoring architectural choices—such as switching from epsilon- to x0-prediction for the one-step variant—to reduce artifacts in extreme rapid-generation settings.
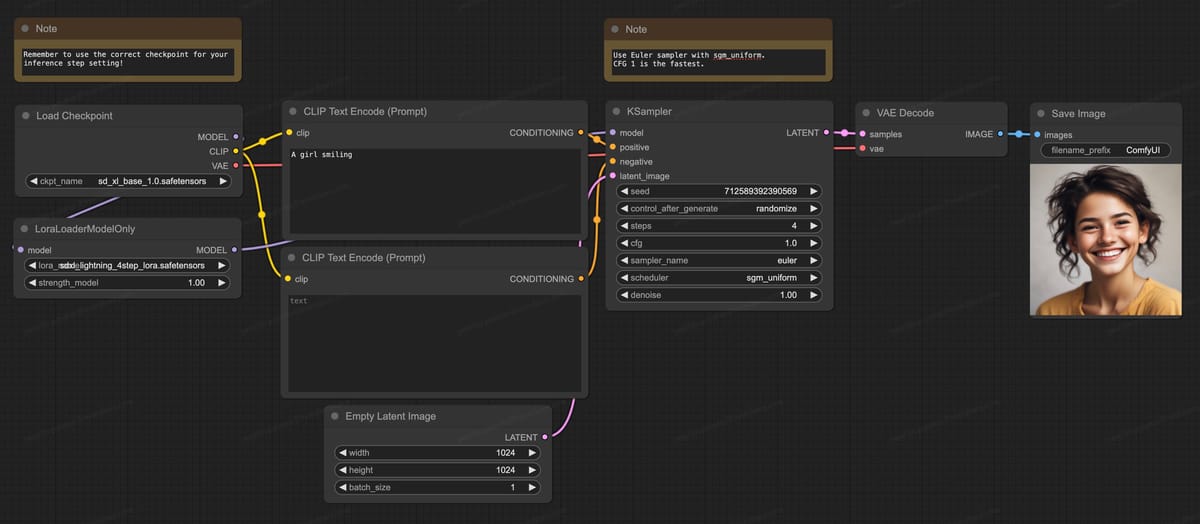
A ComfyUI workflow for generating an image with SDXL-Lightning 4-step LoRA. The diagram details how SDXL-Lightning can be integrated via LoRA, with the prompt 'A girl smiling', demonstrating the resulting image.
SDXL-Lightning's flexibility supports different deployment scenarios. Full UNet checkpoints enable high-fidelity synthesis, while LoRA weights provide efficient, low-overhead upgrades to compatible SDXL models—preserving stylistic and structural features while improving generation speed. This structure enables SDXL-Lightning to be used for both direct production of photorealistic images and as an accelerator within existing creative and editing pipelines.
The model’s rapid inference supports interactive, real-time, or high-throughput workflows where immediate feedback is crucial. Compatibility with conditional generative tools—such as ControlNet-driven tasks—broadens its applicability into areas like compositional editing, controlled augmentation, or context-aware image creation.
SDXL-Lightning’s robustness to aspect ratio variation, while trained primarily on square formats, enables generalization to a variety of output shapes, though minor quality trade-offs may appear in extreme one- or two-step, non-square generations.
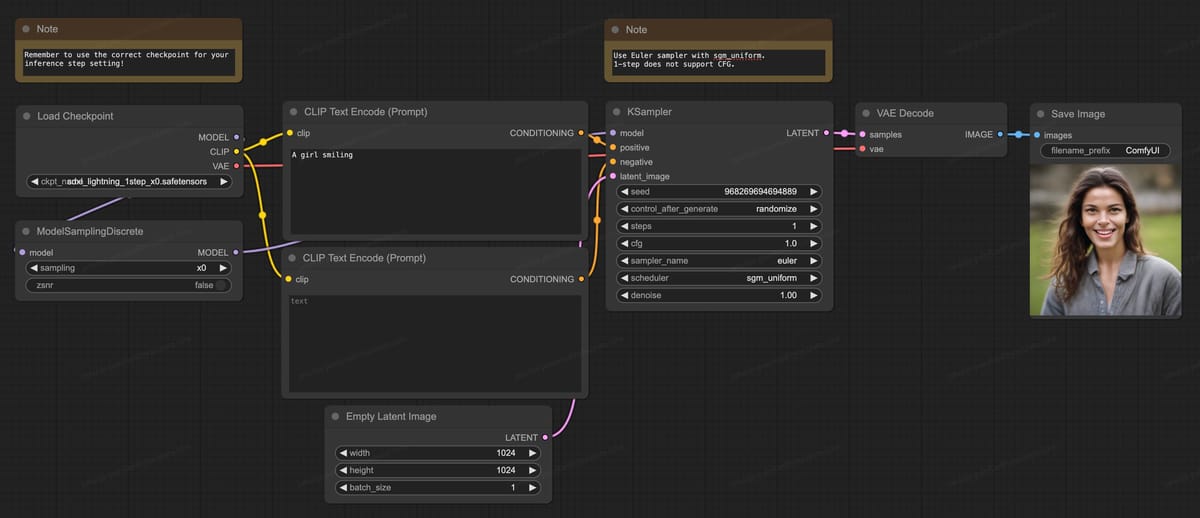
ComfyUI workflow for SDXL-Lightning's experimental 1-step full UNet variant, illustrating generation of 'A girl smiling' in a single inference step.
While SDXL-Lightning advances rapid, high-fidelity image synthesis, it also presents certain constraints. Separate model checkpoints are required for each inference step setting, in contrast to models that support dynamic step counts from a single checkpoint. Quality may degrade for non-square aspect ratios or for extreme few-step generations, particularly at one step, where the architecture’s reliance on the decoder increases. Additionally, LoRA versions are currently unavailable for the one-step variant due to the substantial architectural modifications needed. A trade-off exists in balancing strict mode coverage with semantic correctness, meaning some rare, highly specific features present in the original teacher distribution may be deprioritized for overall image accuracy.
Licensing and Availability
SDXL-Lightning is released as an open-source research model, with checkpoints, code, and documentation available under its official repositories. Its LoRA and full model weights facilitate integration into a range of diffusion model-based applications and research environments.