Launch a dedicated cloud GPU server running Laboratory OS to download and run Zephyr 7B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
HuggingFaceH4 / Zephyr 7B
Zephyr 7B is a 7-billion parameter conversational language model developed by HuggingFaceH4, based on the Mistral-7B architecture and fine-tuned using Direct Preference Optimization. The model is trained on synthetic dialogue data from UltraChat and aligned using preference pairs from UltraFeedback, demonstrating strong performance on conversational benchmarks while being optimized for assistant-oriented dialogue tasks and released under the MIT License.
Explore the Future of AI
Your server, your data, under your control
Zephyr 7B Beta is a generative language model in the Zephyr series, designed for assistant-oriented dialogue tasks. Featuring 7 billion parameters, Zephyr 7B Beta is based on the Mistral-7B-v0.1 architecture, and is notable for its use of Direct Preference Optimization (DPO) during fine-tuning. Developed with a focus on conversational performance, the model is trained predominantly on English and released under the MIT License.
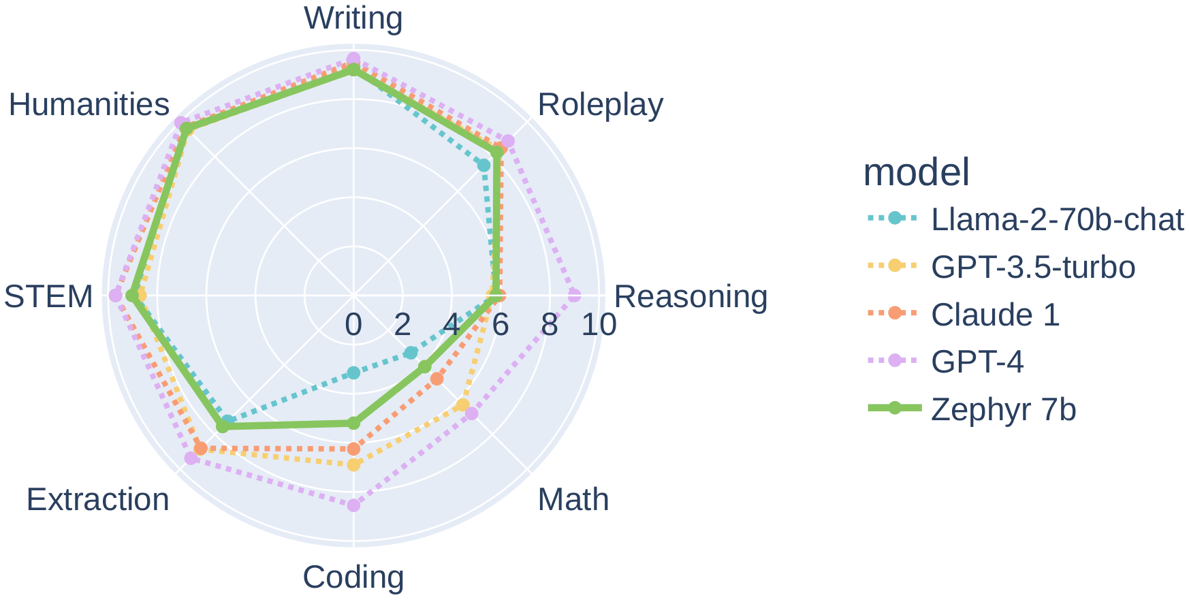
Zephyr-7B-β performance compared to larger language models on MT-Bench categories, including Writing, Roleplay, Coding, and Math.
Zephyr 7B Beta is rooted in the transformer-based Mistral-7B-v0.1 foundation, following the architecture principles established for autoregressive language modeling. The application of Direct Preference Optimization (DPO) serves as an alternative to conventional reinforcement learning approaches for alignment. DPO enables the model to directly learn from preference data—pairs of model completions ranked in order of desirability—without the need for reward models or separate policy optimization stages.
During fine-tuning, Zephyr 7B Beta employs a chat-specific template to format interactions, supporting system and user role distinctions. The development pipeline explicitly removes alignment constraints found in source datasets, resulting in improved benchmark scores but also introducing the possibility of generating unsafe outputs when deliberately prompted.
Training Datasets and Methodology
The training of Zephyr 7B Beta unfolds in a two-step process. The initial phase utilizes a filtered and preprocessed version of the UltraChat dataset, which comprises synthetic conversational dialogues generated by ChatGPT. This stage imparts base conversational and instructional skills to the model.
The subsequent alignment phase applies DPO using UltraFeedback, a dataset containing 64,000 prompts and corresponding model completions, each subject to ranking by GPT-4. The alignment process proceeds via the DPOTrainer from the TRL library, leveraging preference pairs to nudge the model toward more desirable outputs. Complete documentation of the training corpus is provided in the Zephyr-7B-β dataset collection. The underlying data for the parent model, Mistral-7B, is not fully disclosed but is presumed to be a mixture of curated web and technical resources.
Performance and Benchmark Results
Zephyr 7B Beta demonstrates competitive performance among similarly sized open models on standard benchmarks, including MT-Bench and AlpacaEval. Upon release, Zephyr 7B Beta achieved the highest MT-Bench score for a 7B parameter open chat model, reporting an MT-Bench score of 7.34 and a 90.60% win rate on AlpacaEval. These results surpass other peer open-source models in the same parameter class, such as Xwin-LMv0.1 and Mistral-Instruct-v0.1.
The Open LLM Leaderboard further details performance across a range of tasks, with representative metrics including an average leaderboard score of 52.15, strong results on HellaSwag (84.36) and Winogrande (77.74), and more modest performance on GSM8K and DROP, indicating coding and mathematical reasoning as relative weaknesses. DPO fine-tuning resulted in an evaluation loss of 0.7496 and a reward/accuracy metric of 0.7812 during training.
A radar chart visualization depicts Zephyr-7B-β’s strengths in categories like Writing, Roleplay, and Reasoning, while trailing proprietary and much larger models such as GPT-4 or Llama2-Chat-70B in Coding and Mathematics. This highlights the model's proficiency in general assistant tasks, with ongoing challenges remaining in complex technical domains.
Use Cases, Functionality, and Limitations
Zephyr 7B Beta is tailored for text-based chat applications, where it acts as an AI assistant engaging in multi-turn dialogue. The use of a structured chat template makes it suitable for deployments that distinguish between different message roles, such as system instructions and user queries.
While Zephyr 7B Beta provides robust conversational abilities and demonstrates strong performance on general benchmarks, several limitations are noted. The absence of reinforcement learning-based safety alignment and in-the-loop content filtering means the model can generate problematic or unsafe text when deliberately prompted. Furthermore, its performance in specialized reasoning tasks, particularly complex mathematical or programming problems, does not yet reach the level of the latest proprietary systems. The precise details of the Mistral-7B base data remain undisclosed, which limits transparency regarding source text distributions.
Comparison to Related Models
Zephyr 7B Beta is the second entry in the Zephyr line, following Zephyr-7B-α, which scored 6.88 on MT-Bench compared to Zephyr 7B Beta’s 7.34. As with its predecessor, Zephyr 7B Beta focuses on efficient conversational alignment, but benefits from procedural advancements in preference-based training. Other competitor models of similar scale include MPT-Chat and Xwin-LMv0.1, which exhibit lower evaluated scores according to public leaderboards and benchmarks at the time of Zephyr 7B Beta’s release.
Licensing and Availability
Zephyr 7B Beta is released under the MIT License, enabling broad use, modification, and redistribution in compliance with open-source standards. Detailed technical information and model weights are publicly accessible for research and development purposes.