Launch a dedicated cloud GPU server running Laboratory OS to download and run Vicuna 13B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
lmsys / Vicuna 13B
Vicuna-13B is an open-source conversational language model developed by LMSYS based on the LLaMA architecture. Fine-tuned on approximately 70,000 user-shared ChatGPT conversations, it achieves 92% of ChatGPT's response quality according to GPT-4 evaluations while supporting 2048-token context windows. The model demonstrates strong general conversational abilities but shows limitations in specialized domains like mathematics and programming compared to proprietary models.
Explore the Future of AI
Your server, your data, under your control
Vicuna-13B is an open-source large language model developed by LMSYS and introduced on March 30, 2023. Building upon the LLaMA architecture, Vicuna-13B is fine-tuned using a substantial dataset of user-shared conversations, enabling it to operate as a conversational AI chatbot suitable for research and development in natural language processing (NLP) and artificial intelligence (AI). The model is recognized for its open accessibility and detailed documentation, fostering transparency in the study and advancement of language models.
Stylized mascot artwork representing the Vicuna-13B model, inspired by the animal vicuña.
Vicuna-13B is based on the auto-regressive transformer architecture established in LLaMA, with enhancements directed at chatbot performance. The model is fine-tuned on the LLaMA foundation model using approximately 70,000 user-shared ChatGPT conversations collected from ShareGPT, later expanded to about 125,000 conversations for subsequent iterations such as Vicuna v1.5. Fine-tuning is performed with a focus on multi-turn dialogues, where the training loss is computed exclusively on the chatbot's responses, an approach that increases training efficiency and dialogue fluency.
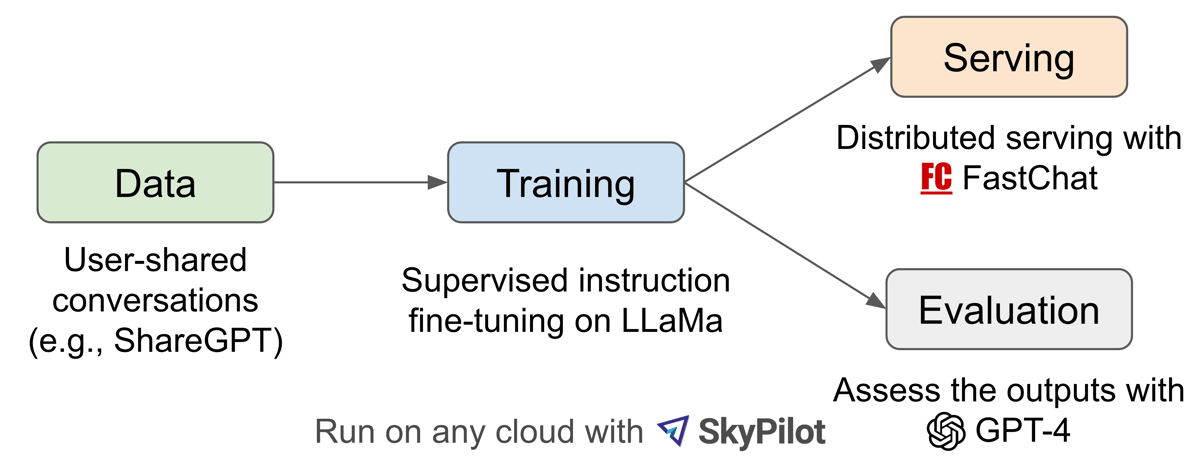
Technical improvements in Vicuna-13B facilitate support for longer conversational contexts, extending the maximum context window from 512 tokens (as in Alpaca) to 2048 tokens. To accommodate the increased computational demand, memory optimization techniques such as gradient checkpointing and FlashAttention are employed during training. The training pipeline is implemented in PyTorch FSDP, typically utilizing clusters of A100 GPUs. For serving, the system incorporates distributed serving infrastructure that supports scalable deployment.
Workflow diagram summarizing Vicuna's data collection, training, serving, and evaluation pipeline.
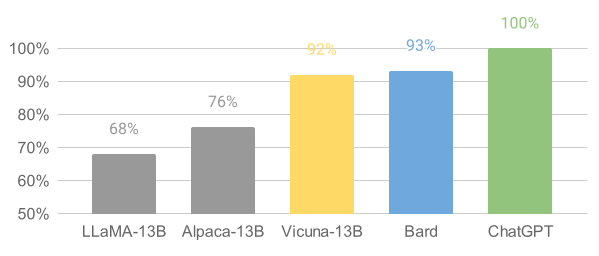
The performance of Vicuna-13B has been systematically evaluated using both language model and human assessments. Notably, the MT-Bench evaluation, in which responses are scored by GPT-4, provides a comparative assessment across multiple chatbot models. According to these studies, Vicuna-13B achieves a relative response quality assessed by GPT-4 at 92% of ChatGPT's performance and closely matches proprietary models such as Bard.
Bar chart of relative response quality as assessed by GPT-4 for various chatbot models, showing Vicuna-13B achieving 92% of ChatGPT's performance.
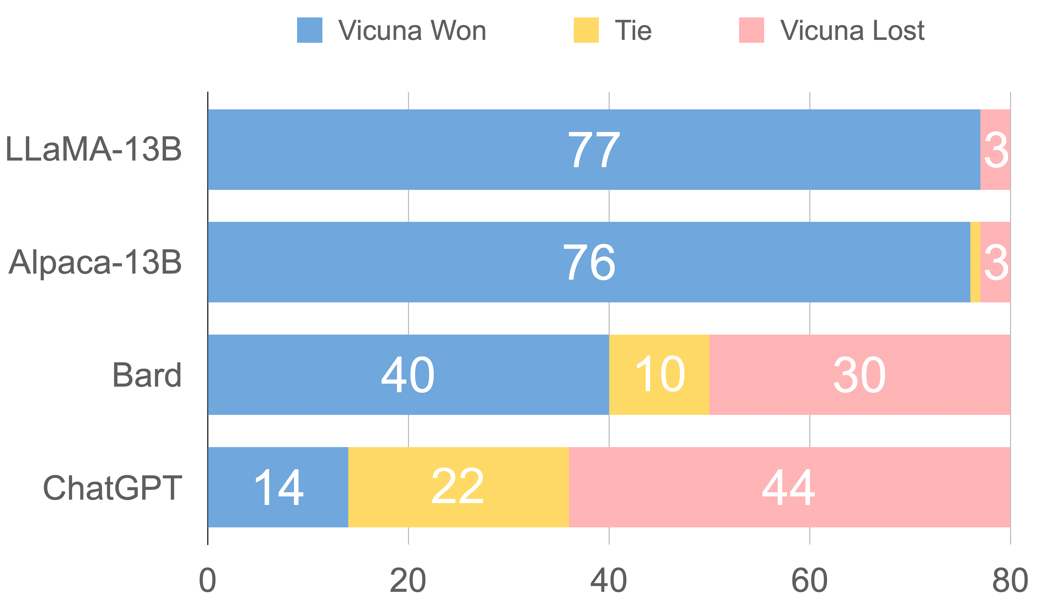
Benchmarking details demonstrate Vicuna-13B's strong comparative preference against open-source models. In direct comparisons, GPT-4 judges selected Vicuna-13B's responses over those of LLaMA-13B and Alpaca-13B in over 90% of prompts, and in approximately 45% of cases, Vicuna-13B's answers were rated as equivalent to or better than those of ChatGPT.
Stacked bar chart illustrating Vicuna-13B's comparative win/tie/loss rates against LLaMA-13B, Alpaca-13B, Bard, and ChatGPT based on GPT-4's evaluation.
Despite these results, Vicuna-13B exhibits lower effectiveness in specialized domains such as mathematics, reasoning, and programming when compared to the latest proprietary models, including GPT-3.5 and GPT-4. This indicates a proficiency for general conversation and writing tasks, but reveals limits in more technical areas.
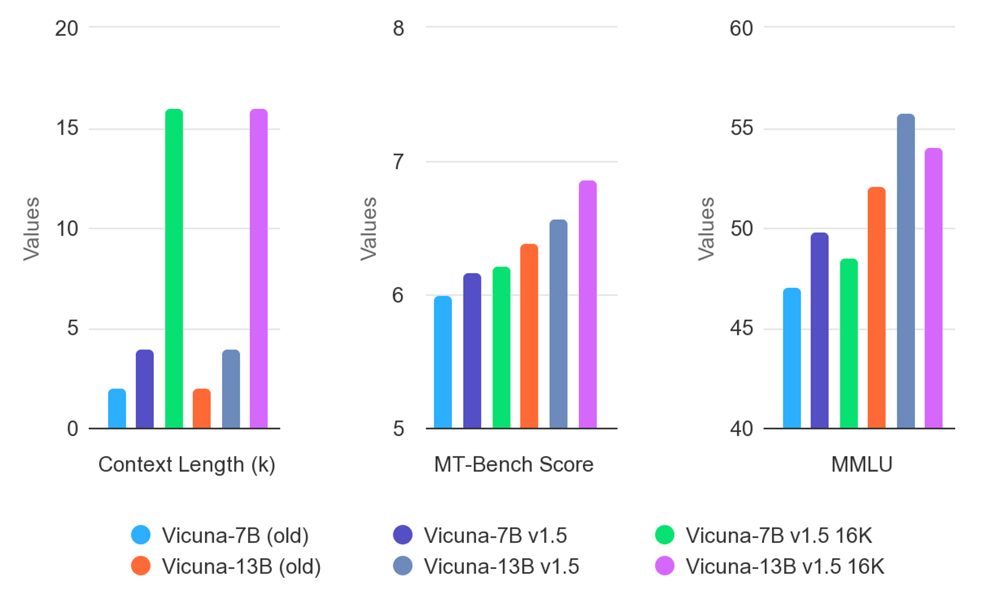
Comparative evaluation graphs for different Vicuna versions, covering context length, MT-Bench score, and MMLU benchmarks.
Vicuna-13B leverages a data-driven approach, utilizing conversation datasets sourced primarily from the ShareGPT platform. These datasets comprise user-contributed, multi-turn dialogues with ChatGPT, supporting the development of more contextually aware chatbot responses. The fine-tuning process incorporates techniques first established in Stanford Alpaca, but with critical modifications such as tuning specifically on the chatbot-generated outputs for improved dialogue consistency. The model's training process emphasizes memory efficiency to allow for larger context lengths, with further cost optimizations achieved by utilizing tools like SkyPilot to manage compute resources.
Demonstration of the Vicuna-13B chatbot responding to queries in a user-facing interface. [Source]
Applications, Limitations, and Model Family
Vicuna-13B is primarily targeted for research applications, such as large language model development, chatbot prototyping, and benchmarking studies. It provides an accessible platform for experimentation in NLP and is particularly suited for researchers and practitioners interested in open research ecosystems.
As with many large language models, Vicuna-13B has certain limitations. Its performance in abstract reasoning, mathematics, and coding remains behind that of contemporary proprietary models. Additionally, while it achieves strong general conversational ability, there exist concerns regarding self-identification, factual precision, and the potential for generating biased or unsafe outputs. The evaluation methodology—often relying on "LLM-as-a-judge" techniques using models like GPT-4—also introduces biases, such as position or verbosity bias, which are the subject of ongoing research and refinement, as explored in the MT-Bench paper.
Vicuna-13B is part of a broader family of models sharing the LLaMA foundation, including related variants like Vicuna-7B and models such as Alpaca-13B, but distinguishes itself through enhancements in conversational quality and extended context handling.
Licensing and Availability
Vicuna-13B is distributed under the Llama 2 Community License Agreement due to its reliance on Llama models as a base. Additionally, any use of Vicuna-trained weights and user-shared conversations must adhere to associated terms, including the OpenAI data usage policies and ShareGPT's privacy practices. The supporting codebase is made publicly available under the Apache License 2.0, facilitating broad collaboration within the research community.