Vicuna-7B is an open-source chatbot created by the LMSYS team through fine-tuning the LLaMA language model. As detailed in the original announcement, it represents a significant advancement in accessible, high-quality language models, achieving impressive performance while maintaining reasonable training costs.
Architecture and Training
The model is based on the transformer architecture and was initially developed as a fine-tuned version of LLaMA, later updated to use Llama 2 as its base for version 1.5. The training process utilized approximately 125,000 conversations sourced from ShareGPT.com, representing a substantial improvement over previous approaches. The training configuration included:
- Global batch size of 128
- Learning rate of 2e-5
- 3 epochs (5 epochs for high-quality subset)
- 8x A100 GPUs
- Implementation of FlashAttention for memory efficiency
- SkyPilot managed spot instances for cost optimization
The total training cost was approximately $140, making it an economically viable option for research and development. The training process improved upon the Stanford Alpaca methods by better handling multi-turn conversations and increasing the maximum context length from 512 to 2048 tokens.
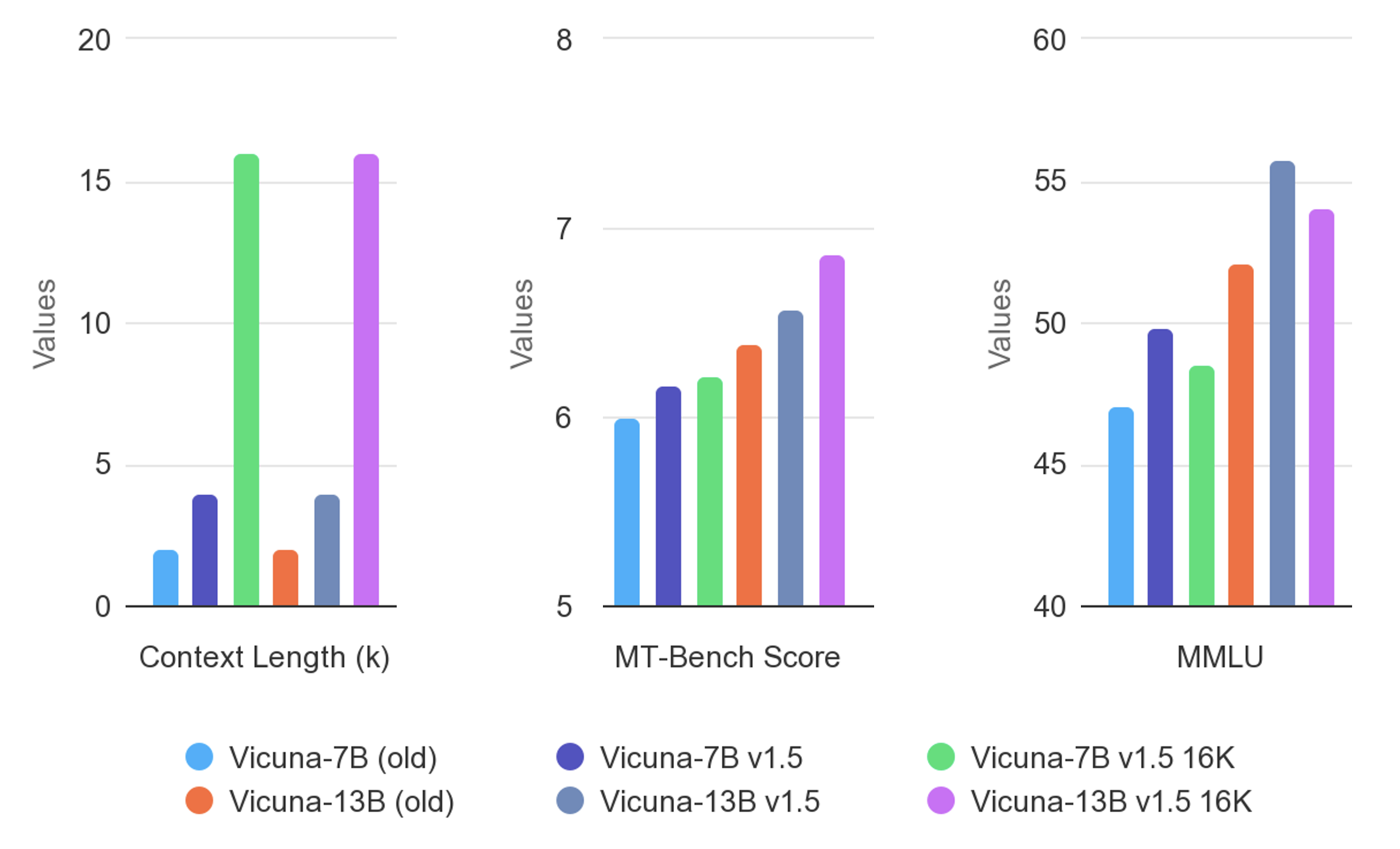
Performance and Evaluation
The model's performance has been extensively evaluated through multiple methodologies, as detailed in the evaluation paper. A preliminary evaluation using GPT-4 as a judge showed that Vicuna achieved over 90% of the quality of ChatGPT and Google Bard, surpassing both LLaMA and Stanford Alpaca in over 90% of cases.
The evaluation framework included:
- MT-bench (multi-turn questions)
- Chatbot Arena (crowdsourced evaluation)
- Standard benchmarks like MMLU and TruthfulQA
- LLM-as-a-judge methodology
The research demonstrated that strong LLMs like GPT-4 can accurately reflect human preferences in evaluating other LLMs, achieving over 80% agreement with human judgments. This validation approach has proven both scalable and explainable, though the authors acknowledge certain limitations in Vicuna's performance on reasoning, mathematics, and factual accuracy tasks.
Model Variants and Applications
Vicuna is available in both 7B and 13B parameter versions, with the 13B variant showing slightly superior performance in most benchmarks. The models are primarily intended for research into LLMs and chatbots, targeting researchers and hobbyists in AI and NLP fields.
The project includes a lightweight distributed serving system capable of handling multiple models and utilizing both on-premise and cloud-based GPU workers. For safety considerations, the online demo employs OpenAI's moderation API to filter inappropriate inputs.
The model is available under the Llama 2 Community License Agreement, and while the code and model weights are publicly available for non-commercial use, the training data itself (the ShareGPT conversations) is not publicly released.
References and Additional Resources
- Vicuna Blog Post - Original announcement and technical details
- Hugging Face Model Page - Model repository and documentation
- Evaluation Paper - Comprehensive evaluation methodology and results
- FastChat Repository - Training and serving code
- Chatbot Arena Leaderboard - Performance comparisons
- MT-bench and Evaluation Data - Benchmark datasets and evaluation tools
- LMSYS Organization Website - Project organization information
- Llama 2 Paper - Base model documentation

