Launch a dedicated cloud GPU server running Laboratory OS to download and run OpenChat 3.5 7B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
openchat / OpenChat 3.5 7B
OpenChat 3.5 7B is a conversational AI model based on Llama 2 7B and fine-tuned using Conditioned Reinforcement Learning Fine-Tuning (C-RLFT). This technique enables training on mixed-quality datasets without requiring human preference labels by treating data sources as reward signals. The model demonstrates strong performance across benchmarks including MT-Bench (7.81) and GSM8K (77.3), with capabilities in general conversation and coding assistance through an 8,192-token context window.
Explore the Future of AI
Your server, your data, under your control
OpenChat 3.5 7B is an open-source large language model developed as part of the OpenChat project, fine-tuned from the Llama 2 7B foundation model. Introduced in 2023, the model leverages a fine-tuning method known as Conditioned Reinforcement Learning Fine-Tuning (C-RLFT). This approach enables training on datasets of mixed quality without the need for human-annotated preference labels. OpenChat 3.5 7B is designed for general-purpose conversational tasks and coding assistance.
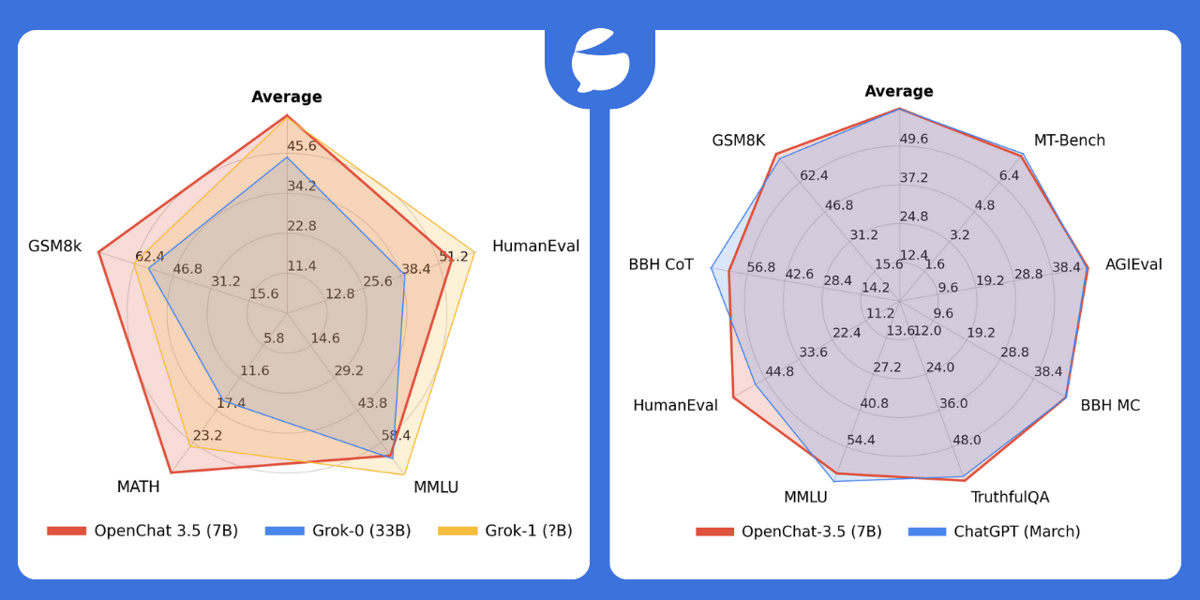
Benchmark comparison radar charts for OpenChat 3.5 (7B) against Grok models and ChatGPT (March) on tasks such as MT-Bench, GSM8K, MMLU, and more.
OpenChat 3.5 7B is built upon the Llama 2 7B architecture, which offers a foundational backbone for instruction-following language models. The defining technical feature of OpenChat 3.5 is its employment of Conditioned Reinforcement Learning Fine-Tuning (C-RLFT). This technique is inspired by approaches from offline reinforcement learning and enables the model to learn from both expert and sub-optimal data without requiring preference labels, rankings, or reward modeling typically seen in RLHF methods.
C-RLFT treats the source of each example (such as being generated by GPT-4 or GPT-3.5) as a coarse-grained reward signal. The model learns a class-conditioned policy, optimizing a KL-regularized RL objective; however, the process can be framed as a single-stage supervised regression task. This RL-free training pipeline reduces computational burdens and resource demands usually associated with reinforcement learning procedures.
The training process also incorporates specific conversation templates, distinct for use cases such as general dialogue or coding tasks. These templates condition the model’s responses, contributing to higher-quality outputs through structured prompting.
Training Data and Procedure
The primary dataset used to train OpenChat 3.5 is a curated collection of instruction-following data, sourced from a variety of public datasets and processed with a tailored pipeline. Central to this dataset is ShareGPT, comprising approximately 70,000 user-shared conversations. Within this corpus, an estimated 6,000 conversations are produced by GPT-4 and labeled as expert-level data, while the remainder are generated by GPT-3.5 and considered sub-optimal. This stratification supports the assignment of reward weights during C-RLFT training.
Fine-tuning is performed for 5 epochs on ShareGPT using the AdamW optimizer with a sequence length of 4,096 tokens and an effective batch size of 200k tokens. Expert data carry more weight in the optimization objective, while sub-optimal data are down-weighted. The learning schedule is cosine-annealed to encourage stable convergence. This methodology allows the model to generalize from high-quality supervision while making use of large volumes of less-reliable data.
Evaluation and Benchmark Performance
OpenChat 3.5 7B reports performance across several established large language model benchmarks. Its results are presented in both research publications and community evaluations, with a MT-Bench score of 7.81, approaching the performance of ChatGPT (March 2023) and outperforming open-source models with larger parameter counts.
Across a range of evaluation tasks, OpenChat 3.5 7B achieves the following scores:
MT-Bench: 7.81
AGIEval: 47.4
BBH MC: 47.6
TruthfulQA: 59.1
MMLU: 64.3
HumanEval: 55.5
BBH CoT: 63.5
GSM8K: 77.3
These results are comparable or superior to certain larger models, including Grok-0 (33B) and Grok-1, particularly in mathematical reasoning and problem-solving tasks such as GSM8k and MATH, as demonstrated by radar chart visualizations in the official model documentation.
Ablation studies reported in the OpenChat research paper indicate that coarse-grained reward labeling and class-conditioned prompting are components of the C-RLFT methodology, confirming their contribution to performance with mixed-quality datasets.
Key Features and Limitations
OpenChat 3.5 7B supports a context window of 8,192 tokens, enabling it to manage longer conversations and complex reasoning over extended inputs. A dedicated coding mode, activated by a specific prompt template, is available for program synthesis and code completion applications. Response generation is structured using prompt templates such as "GPT4 User" and "Code User," with a special <|end_of_turn|> token introduced for explicit speaker demarcation.
The model shares limitations common to LLMs, such as susceptibility to generating hallucinated or inaccurate information, especially on challenging mathematical or reasoning tasks. Safety considerations remain, as outputs are not guaranteed to be free of harmful or biased content. The model’s assumption regarding data quality (e.g., labeling all GPT-4 data as expert) may affect the variability within datasets.
Use Cases and Licensing
OpenChat 3.5 7B is positioned as a general-purpose conversational agent, suitable for chat-based assistance, instructional following, and programming support. Its benchmarks indicate competency in a variety of domains, consistent with the goals of instruction-tuned LLMs. The model and accompanying code resources are released under the Apache License 2.0, encouraging open research and development.
External Resources
For further exploration, key resources associated with OpenChat 3.5 7B include: