Launch a dedicated cloud GPU server running Laboratory OS to download and run ControlNet SDXL IP Adapter using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
h94 / ControlNet SDXL IP Adapter
ControlNet SDXL IP Adapter is a neural network module that enhances Stable Diffusion XL models by enabling image prompt conditioning alongside traditional text prompts. The adapter uses a decoupled cross-attention mechanism and contains approximately 22 million trainable parameters while keeping the base diffusion model frozen. It supports multimodal image generation, style transfer, and image variation tasks with competitive performance on benchmarks like COCO2017.
Explore the Future of AI
Your server, your data, under your control
ControlNet SDXL IP-Adapter is a neural network module designed to enhance the flexibility of text-to-image diffusion models, allowing them to effectively utilize image prompts in addition to traditional text-based inputs. Developed as an Image Prompt Adapter (IP-Adapter), it operates as a lightweight add-on that integrates with pre-trained diffusion models such as Stable Diffusion and Stable Diffusion XL (SDXL), enabling sophisticated multimodal image generation while maintaining high computational efficiency. This model was introduced to address challenges associated with text-based prompt engineering, which can be insufficient for expressing complex visual concepts or replicating specific subject details. By introducing a decoupled cross-attention mechanism, the IP-Adapter enables more nuanced and information-rich conditioning, supporting both image and text prompts, and facilitating new creative and practical applications in image synthesis and editing.
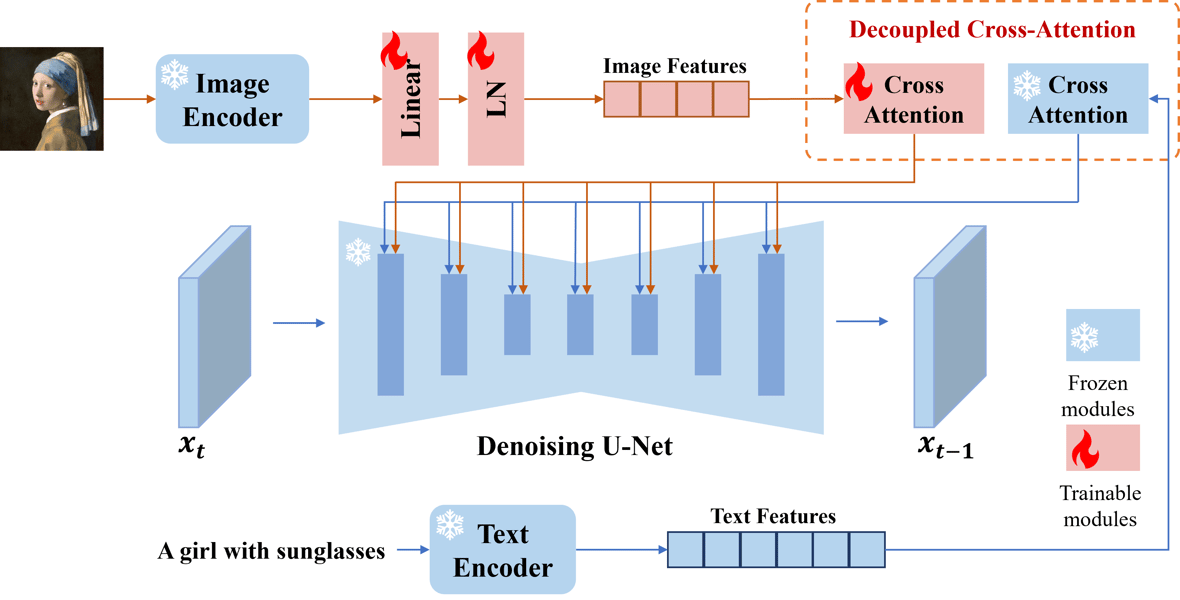
The IP-Adapter architecture integrates a dedicated image encoder and novel cross-attention layers into the diffusion framework, allowing flexible conditioning on both image and text prompts.
The core design of the IP-Adapter centers on a decoupled cross-attention mechanism, which enables effective fusion of image and text features within pre-trained diffusion models. Unlike earlier approaches that concatenate or merge embeddings, this method introduces an independent cross-attention path dedicated to the image prompt. This structural innovation preserves the specific information contained in the input image features while maintaining the integrity of text conditioning.
The IP-Adapter comprises two main components: a frozen image encoder, typically based on the OpenCLIP architecture, and a lightweight set of additional cross-attention layers within the denoising UNet of the diffusion model. The image encoder, trained on large-scale datasets, extracts global or fine-grained image features which are then projected to match the dimensionality of the model’s text features. During operation, for each cross-attention layer in the UNet, the adapter inserts a new, trainable cross-attention unit to process image-derived features, while leaving the rest of the diffusion model parameters untouched. This modular approach results in an efficient parameter footprint—the standard IP-Adapter contains approximately 22 million parameters—while ensuring high adaptability to various downstream image synthesis tasks.
The synergy between the decoupled attention strategy and pretrained foundation models allows seamless multimodal prompting, with dedicated controls to balance the influence of text and image inputs.
Training Methodology and Data
The training of the IP-Adapter is grounded in large-scale multimodal datasets containing paired images and captions, such as LAION-2B and COYO-700M. Training is carried out without altering the underlying diffusion model, which remains fixed during the adapter's optimization process. This approach aligns with the principle of parameter efficiency and rapid adaptability.
The adapter is jointly trained on image and text conditions, using a loss function analogous to that of Stable Diffusion, encouraging the generation of outputs that are consistent with both visual and textual prompts. To enhance flexibility and enable classifier-free guidance during inference, conditioning on image and text is randomly dropped with a controlled probability. For expansive models such as Stable Diffusion XL (SDXL), a two-stage training regimen is employed, involving initial pretraining at 512x512 resolution followed by multiscale fine-tuning to better accommodate higher-resolution generation tasks.
Through these methods, the IP-Adapter learns to project diverse visual information into a form compatible with the existing diffusion generator, supporting applications ranging from simple image variation to sophisticated multimodal synthesis.
Technical Capabilities and Performance
ControlNet SDXL IP-Adapter unlocks a range of advanced capabilities for conditional image generation. Principally, it enables diffusion models to synthesize new images conditioned on arbitrary input images, functioning as an image-to-image variation system or as an instrument for style transfer and inpainting tasks. Notably, the adapter achieves this with comparatively minimal computational resources, while delivering performance comparable to or surpassing fully fine-tuned image-conditioned diffusion models.
Performance evaluation on benchmark datasets such as COCO2017 has demonstrated that IP-Adapter attains strong alignment to reference images and textual descriptions, as indicated by key metrics like CLIP-I (image-to-image similarity) and CLIP-T (image-to-text similarity) scores. For example, on this benchmark, the adapter achieves a CLIP-I of 0.828 and a CLIP-T of 0.588—metrics that indicate competitive or superior performance relative to previous adapters and fully fine-tuned diffusion systems, as detailed in the original publication on arXiv.
Direct comparison of image generations from IP-Adapter with [Stable Diffusion XL (SDXL)](https://openlaboratory.ai/models/sdxl) and other diffusion models, demonstrating fidelity and diverse stylistic capabilities.
The introduction of fine-grained feature conditioning, as seen in the IP-Adapter Plus variant, enhances the model’s ability to capture detailed spatial information from input images, though this sometimes comes at the expense of reduced diversity in outputs.
Variations generated with IP-Adapter Plus showcase the model’s capacity to reproduce intricate image details based on fine-grained image encoding.
The versatility of ControlNet SDXL IP-Adapter makes it suitable for a broad spectrum of image generation and editing applications. Through conditioning on both image and text prompts, users can generate novel variations of source images, perform guided inpainting, and integrate additional structural cues via tools like ControlNet or T2I-Adapter, all without the need for further adapter fine-tuning. This approach streamlines workflows in fields such as visual art exploration, rapid iteration in creative industries, and data augmentation for training AI systems.
The adapter’s compatibility with non-square images, albeit with best results for square-cropped inputs due to the CLIP processor, further broadens its applicability. Additionally, its seamless multimodal prompt integration allows for granular editing, for example, modifying a subject’s pose or attributes using a combination of a reference image and specific text.
Combining an image prompt (marble bust) and a text prompt ('wearing a hat on the beach') to generate novel subject variations and scene compositions.
Face-guided image generation is also supported, enabling outputs that align with an input portrait across different styles and contexts—a capability demonstrated by dedicated face-oriented adapter variants.
Demonstration of generating stylized portraits from a face image prompt and text, including transitions to both realistic and anime-themed outputs.
While the IP-Adapter extends diffusion models with enhanced flexibility and multimodal conditioning, certain limitations remain. The current approach is less proficient at ensuring strict subject identity consistency across generations when compared to methods like Textual Inversion or DreamBooth, which are explicitly designed for personalized subject fidelity. Outputs from the adapter tend to retain style and content, but may not perfectly preserve fine subject semantics.
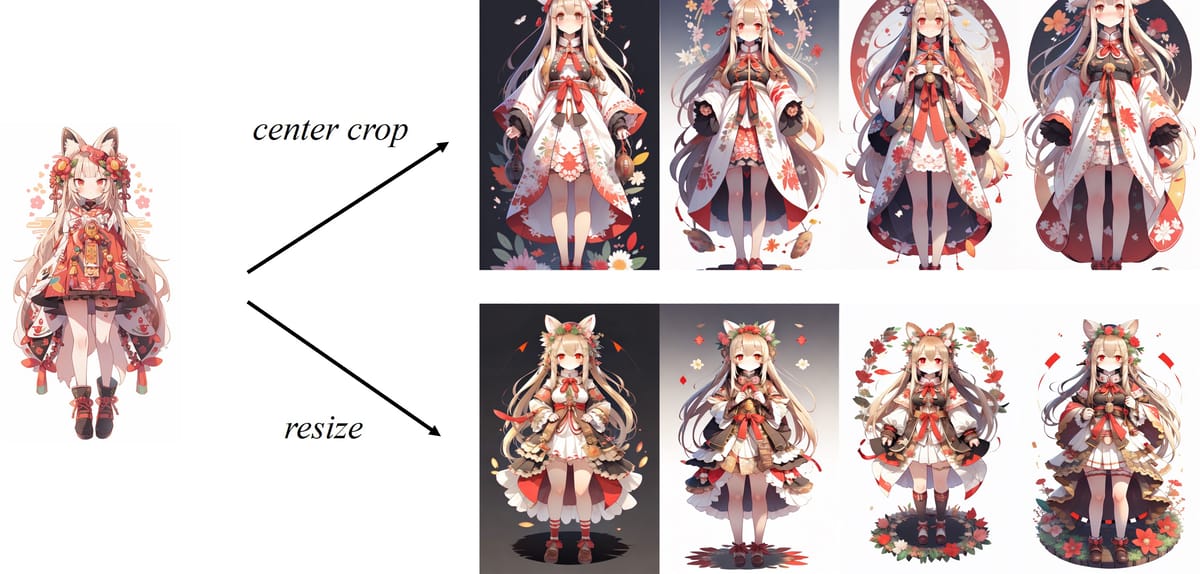
In addition, while the adapter supports non-square images through resizing operations, optimal results are typically achieved with central, square-cropped inputs due to the architectural constraints of the employed image encoder.
Comparison of model outputs using center crop versus resize operations on non-square anime-style input, highlighting information retention differences.
Despite these caveats, the modularity of the IP-Adapter and the pace of new releases suggest ongoing improvements in adaptability and performance.
Release and Licensing
The IP-Adapter, including its Stable Diffusion XL (SDXL)-compatible variants, is distributed under the Apache 2.0 license, promoting scientific transparency and ease of integration into open source and research projects. Major milestones include the initial release in August 2023, successive expansion to support Stable Diffusion XL (SDXL), the addition of fine-grained feature conditioning, dedicated face prompt adapters, and broader compatibility with community toolchains such as Diffusers, WebUI, and ComfyUI.