Launch a dedicated cloud GPU server running Laboratory OS to download and run ControlNet SD 1.5 Lineart Anime using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
lllyasviel / ControlNet SD 1.5 Lineart Anime
ControlNet SD 1.5 Lineart Anime is a specialized image generation model that transforms anime-style lineart sketches into colored illustrations conditioned on textual prompts. Built upon Stable Diffusion 1.5 with additional ControlNet layers, it processes both manually created and algorithmically extracted line drawings. The model utilizes extended token length and CLIP skip 2 parameters for enhanced prompt comprehension, enabling detailed character and scene synthesis from minimal lineart input combined with descriptive text guidance.
Explore the Future of AI
Your server, your data, under your control
ControlNet SD 1.5 Lineart Anime is a specialized generative AI model designed to synthesize anime-style images from lineart inputs, leveraging the capabilities of Stable Diffusion 1.5. As part of the ControlNet 1.1 model suite developed by lllyasviel, this variant focuses on providing users with enhanced control over the image generation process using anime line drawings as the primary condition. The model has been developed with refined training methodologies and targeted adjustments to improve its robustness and output quality for anime-style illustrations.
Model outputs for the prompt '1girl, in classroom, skirt, uniform, red hair, bag, green eyes' from the ControlNet 1.1 Anime Lineart model, illustrating its ability to generate colored anime-style images from lineart inputs. The user interface displays prompt text, settings, and the resulting images.
ControlNet SD 1.5 Lineart Anime is built upon the Stable Diffusion 1.5 architecture, utilizing the “v1-5-pruned.ckpt” checkpoint as its foundational model. The essential innovation in ControlNet consists of integrating additional trainable blocks, known as ControlNet layers, that are attached parallel to the existing U-Net encoder structure within Stable Diffusion. This arrangement enables the model to condition image synthesis on external signals—in this case, anime linearts—without the need to retrain the entire diffusion network from scratch.
Specifically, the Lineart Anime variant processes both real and algorithmically-extracted anime line drawings. A notable technical aspect is its training using threefold token length and CLIP skip 2, allowing it to respond more effectively to longer, semantically complex prompts. To properly implement custom inference, developers are advised to insert a global average pooling operation between the ControlNet encoder and the Stable Diffusion U-Net layers, applying ControlNet only on the conditional branch of CFG scaling. The model does not offer a "Guess Mode" feature, directing all control through explicit lineart and prompt guidance.
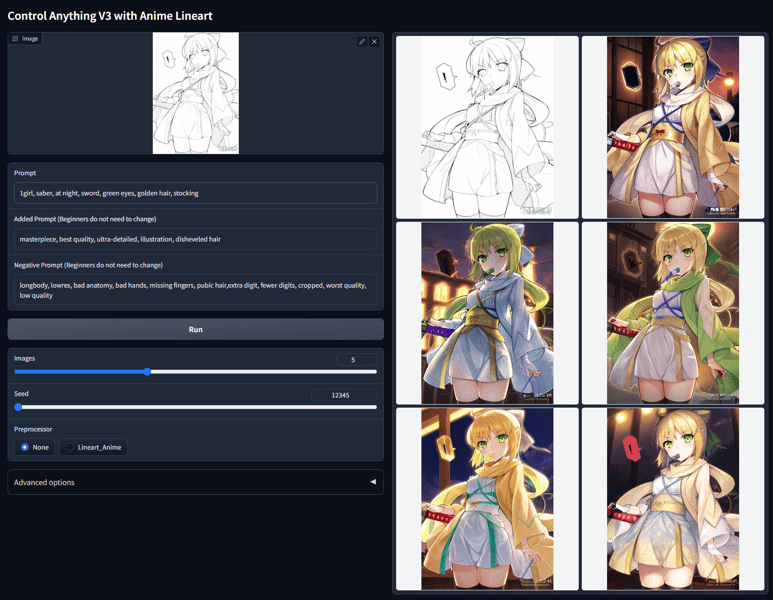
Interface demonstration of the ControlNet Anime Lineart model using the prompt '1girl, saber, at night, sword, green eyes, golden hair, stocking'. The image highlights how various outputs are generated from a single lineart input and descriptive prompt.
While the precise composition of the Lineart Anime model’s training dataset remains undisclosed, the developers specify that improvements were made over previous versions. Earlier issues—such as duplicated or mismatched training pairs and low-quality source material—have been addressed through more stringent data curation and advanced data processing pipelines. The model is engineered to handle both manually created and algorithmically extracted line drawings. The configuration involving extended token length and CLIP skip parameters facilitates nuanced prompt comprehension, leading to improved correspondence between input instructions and generated imagery.
Reference to the training process for the broader ControlNet 1.1 suite reflects extensive computational investment, utilizing high-performance GPUs such as Nvidia A100s to achieve model convergence. However, only general guidance about dataset composition and optimization procedures is publicly disclosed.
Example batch generation from complex input lineart and the prompt '1girl, Castle, silver hair, dress, Gemstone, cinematic lighting, mechanical hand, 4k, 8k, extremely detailed, Gothic, green eye', showing model diversity and output fidelity based on provided conditions.
The central purpose of ControlNet SD 1.5 Lineart Anime is to transform anime-style lineart sketches into fully realized, colored illustrations in response to textual prompts. This model excels in scenarios requiring precise translation from an outline drawing to a detailed, prompt-driven anime image. For artists and researchers, this facilitates:
Digital colorization of manually sketched or extracted lineart, enabling streamlined workflows for creating finished anime images from concept drawings.
Character and scene synthesis from minimal input, where simple outlines and prompt descriptors generate sophisticated illustrations consistent with user intent.
Artistic exploration through iterative prompt adjustment, offering creators fine-grained control over pose, setting, and style in the context of anime image synthesis.
The model’s prompt optimization—favoring longer, richly descriptive input—allows for intricate guidance and performs effectively in situations where elaborate or nuanced visual attributes must be specified through text.
Limitations and Considerations
Some limitations are associated with the ControlNet SD 1.5 Lineart Anime model design and ecosystem. The model is not compatible with “Guess Mode”; all control is exerted explicitly via provided lineart and ample prompts. Optimal results are most consistently achieved using lengthy, descriptive prompts, which may present a usability challenge for those less familiar with prompt engineering.
Users must source specific files independently, such as certain model checkpoints referenced in demonstration code. The model is technically aligned with the ControlNet 1.1 family, and while not marked “experimental,” it shares a release framework with other variants that are still in active development. The official ControlNet repository is not an an extension of A1111; users seeking Stable Diffusion web UI integration should look to the recommended sd-webui-controlnet plugin.
Related Models in the ControlNet Suite
ControlNet 1.1 encompasses a diverse series of models that expand conditional control over Stable Diffusion. These include variants tailored for depth maps, normal maps, Canny edges, MLSD straight lines, scribble art, soft edges, segmentation masks, Openpose keypoints, and more. Each model enables a different form of visual conditioning and can often be combined for complex multi-modal guidance, depending on the interface used.
The Lineart Anime variant is specialized for anime-style line work, operating alongside more general-purpose lineart models and other conditioning modes. Adoption and further development within the ControlNet ecosystem continue to expand the control granularity available to generative model practitioners.
Licensing and Research Use
ControlNet SD 1.5 Lineart Anime is distributed for research and academic experimentation, as outlined in the public repository documentation. The licensing framework focuses on scientific transparency and responsible research use, though users are advised to consult the official repository for exact terms and any updates to usage policy.