Launch a dedicated cloud GPU server running Laboratory OS to download and run AlbedoBase XL using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Model Report
albedobond / AlbedoBase XL
AlbedoBase XL is a Stable Diffusion XL-based image generation model developed by albedobond through merging multiple SDXL models and LoRA modules using proprietary algorithms. The model features approximately 3.5 billion parameters and demonstrates versatility across anime, photorealistic, and artistic styles without requiring a separate refiner. It incorporates custom-trained LoRAs developed through GPT-4V annotation of high-fidelity photographs, enabling nuanced prompt comprehension and compositional clarity across diverse visual domains.
Explore the Future of AI
Your server, your data, under your control
AlbedoBase XL is a generative artificial intelligence model developed to serve as a foundational base for SDXL and features image synthesis capabilities across diverse stylistic domains. Originating from the integration and refinement of multiple SDXL models and LoRA (Low-Rank Adaptation) modules, AlbedoBase XL features advanced merging algorithms and versatility in visual output, with prompt understanding and visual fidelity model details.
Sample output from AlbedoBase XL v3.1-Large demonstrating detailed human figure rendering, elaborate costume design, and complex cosmic backgrounds.
AlbedoBase XL is architecturally based on the SDXL checkpoint, comprising approximately 3.5 billion parameters in its core, not including a refiner. The model is created through an iterative merging strategy, combining weights from numerous community-contributed SDXL-derived models and custom-trained LoRAs. This approach utilizes a proprietary script that aligns U-NET and CLIP block weights non-linearly, resulting in a fine-tuned model with properties characteristic of this blending method details.
Notably, AlbedoBase XL incorporates self-developed LoRAs, one of which was produced through the annotation of 174 high-fidelity photographs using GPT-4V, contributing to the model's compositional clarity and comprehension of nuanced prompts. The merging process relies on extensive evaluation of public model checkpoints and LoRAs—only those demonstrating robust performance in style, realism, and versatility are selected for inclusion.
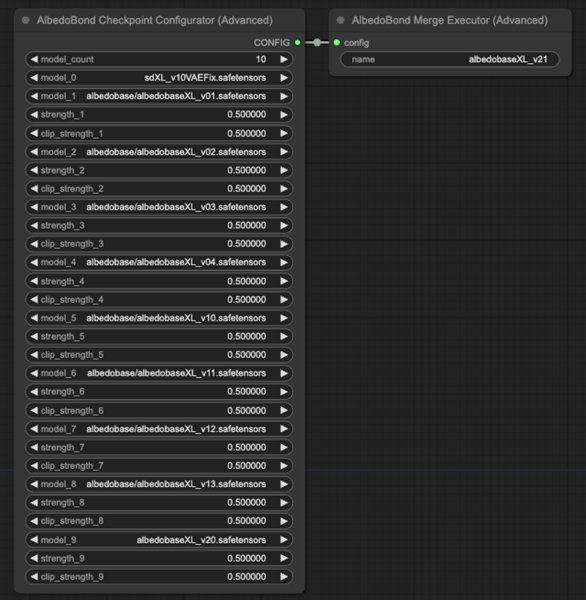
Screenshot of an advanced checkpoint and LoRA merging workflow for AlbedoBase XL v2.1, highlighting detailed configuration controls.
AlbedoBase XL is engineered for broad stylistic versatility, generating images in anime, 2D, 3D, photorealistic, and artistic visual genres model description. It does not require a separate refiner, as a built-in Variational Autoencoder (VAE) is included. The model demonstrates understanding of sentence-form prompts, extracting nuanced instructions for both composition and style, while maintaining fidelity across variable image resolutions.
A characteristic of AlbedoBase XL includes its responsiveness to sampling step count: increased steps correlate with more detail or refinement in generations. The model is compatible with a wide range of diffusion samplers, and experiments indicate that results are influenced by configurations of steps and CFG scales.
The model offers robust performance with default settings, and often achieves visual fidelity when the negative prompt field is left empty, especially in recent versions. However, the inclusion of targeted negative prompts can further reduce artifacts such as asymmetrical facial features or pixelation.
Digital portrait generated by AlbedoBase XL, exhibiting realistic facial features and complex texture rendering. Prompt: woman in galaxy-patterned attire, snowy landscape.
Community feedback describes AlbedoBase XL as providing detailed, clear, and compositionally consistent images, with features in rendering hands, faces, and nuanced lighting. Quantitative benchmarks within user communities cite over 119,000 downloads for the latest version and more than 981,000 total downloads as of May 2025. The model has also garnered a user review score indicating positive reception for prompt sensitivity and stylistic flexibility compared to models with similar applications.
Automated grid benchmarks, performed across a range of samplers, scheduling types, and CFG strengths, visually demonstrate that increasing sampling steps influences fidelity and reduces generation errors. These results are further illustrated by spec grids showing consistent subject rendering and reduction of common diffusion artifacts at higher step counts.
Advanced comparison grid for AlbedoBase XL v3.1-Large output, visualizing the effects of schedule type and CFG scale on image quality at multiple sampling steps.
AlbedoBase XL is applied within a broad range of generative image workflows due to its base model positioning and adaptability. It is suited for artistic illustration, concept art, anime and photorealistic portrait generation, 3D renders, and further fine-tuning by individual users or researchers application guidance. Its capacity for nuanced prompt comprehension allows for control over subject, style, and composition, making it a foundation for specialized downstream models or creative projects.
Stylized portrait of a man in formal attire, exemplifying AlbedoBase XL’s capacity for artistic rendering and expressive character illustration.
Despite its versatility, AlbedoBase XL exhibits certain limitations characteristic of contemporary diffusion-based models. Users have reported isolated prompt recognition bugs, particularly with specific phrase structures that may not be parsed correctly by the underlying CLIP model. Adjusting CLIP SKIP settings or reordering prompt components can often mitigate these issues. Additionally, artifact emergence—such as asymmetrical facial features or detail loss—can occur in challenging prompt scenarios, though targeted negative prompts may ameliorate these defects limitations discussion. Dataset composition may also introduce representational biases; for example, community feedback has noted a tendency for female subjects to be generated more frequently in certain prompts.
Certain licensing restrictions on external models limit the developer’s ability to integrate all desired community checkpoints, and model merging is subject to the terms of the CreativeML Open RAIL++-M license with an addendum.