Stable Diffusion 3.5 Turbo represents a significant advancement in text-to-image generation, launched by Stability AI on October 22nd, 2024. As part of the broader Stable Diffusion 3.5 family, it builds upon previous iterations while introducing key architectural improvements and optimizations for enhanced performance and accessibility.
Architecture and Technical Details
At its core, Stable Diffusion 3.5 Turbo is a Multimodal Diffusion Transformer (MMDiT) that leverages Adversarial Diffusion Distillation (ADD) technology. This architecture enables superior image quality, improved typography, and more sophisticated prompt understanding while maintaining remarkable efficiency. The model employs three fixed, pretrained text encoders:
- OpenCLIP-ViT/G
- CLIP-ViT/L (both with 77 token context length)
- T5-xxl (with variable 77/256 token context lengths during different training stages)
A notable architectural enhancement is the integration of Query-Key (QK) normalization into the transformer blocks, which significantly improves training stability and simplifies fine-tuning processes. More detailed technical specifications can be found in the MMDiT research paper and ADD technical report.
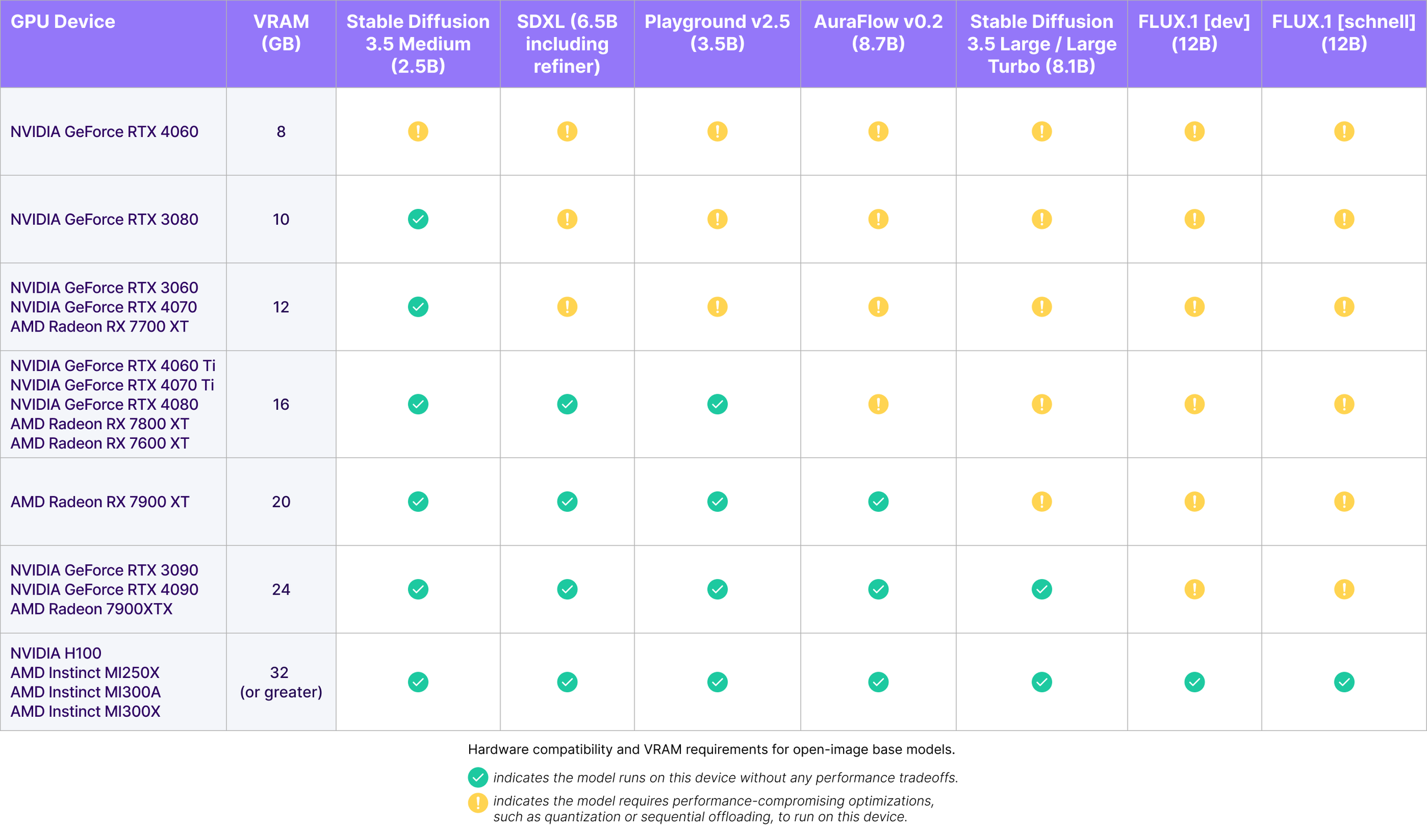
Performance and Capabilities
Stable Diffusion 3.5 Turbo is a distilled version of the larger SD 3.5 Large model, optimized specifically for consumer hardware while maintaining exceptional image quality. One of its most notable features is the ability to generate high-quality images in just 4 inference steps, making it significantly more efficient than previous versions.
The model demonstrates remarkable versatility in generating diverse outputs, from photorealistic images to various artistic styles:

In terms of performance benchmarks, Stable Diffusion 3.5 Large (the base model from which Turbo is distilled) leads the market in prompt adherence and rivals much larger models in image quality:
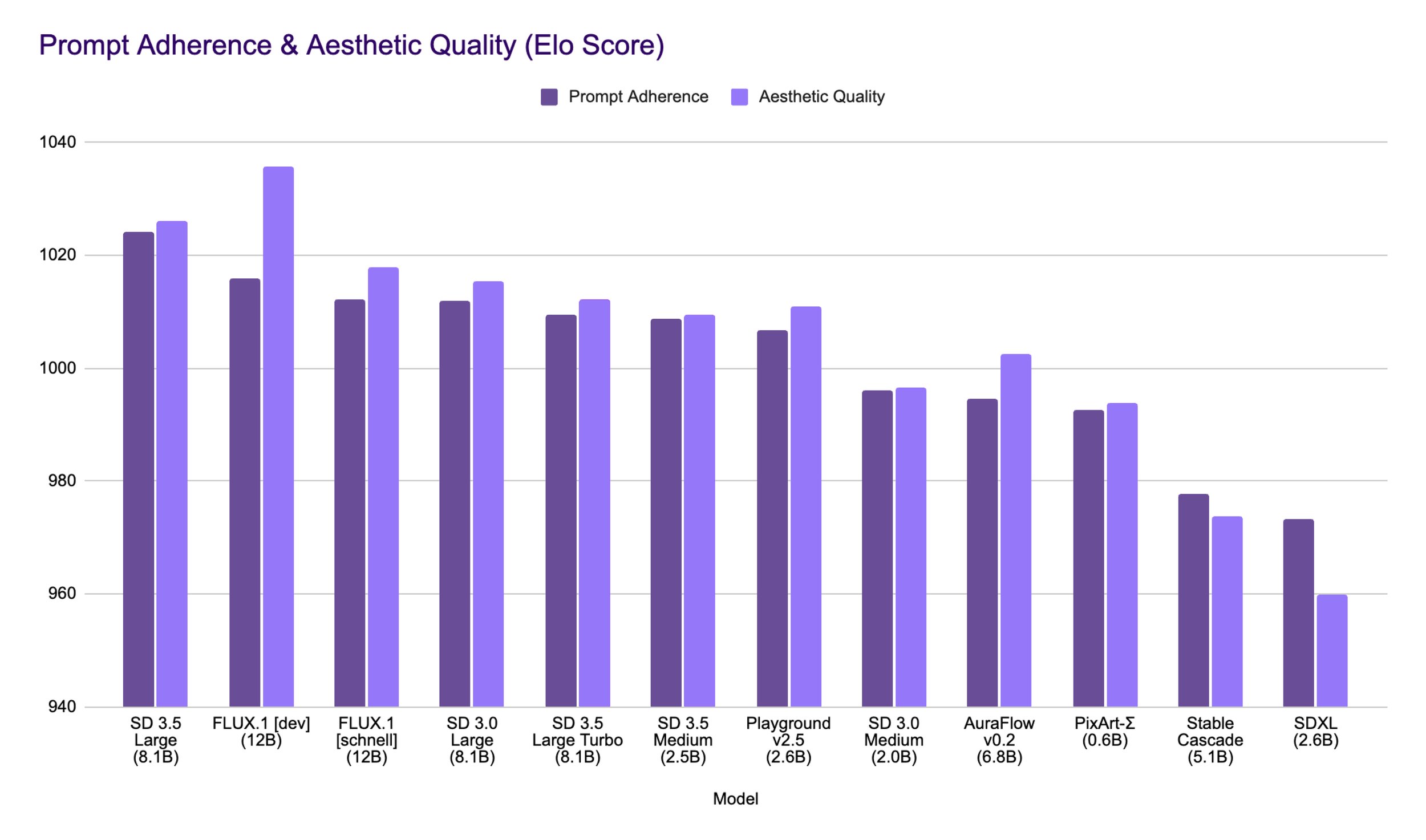
Model Family Comparison and Usage
Within the SD 3.5 family, there are several variants optimized for different use cases:
- Stable Diffusion 3.5 Large: 8.1 billion parameters, ideal for professional use at 1 megapixel resolution
- Stable Diffusion 3.5 Medium: 2.5 billion parameters, requires 9.9 GB VRAM (excluding text encoders)
- Stable Diffusion 3.5 Turbo: Distilled version optimized for consumer hardware and faster inference
The model excels in generating diverse representations of people and features without requiring extensive prompting:

Licensing and Usage Guidelines
The model is released under the Stability Community License, which allows free use for:
- Research purposes
- Non-commercial applications
- Commercial use by organizations with less than $1 million in annual revenue
Stability AI has implemented safety mitigations to reduce harmful content generation risks, though developers are encouraged to implement additional safeguards based on their specific use cases. The model is explicitly not intended for generating factually accurate representations of people or events.
Reference Links

