Launch a dedicated cloud GPU server running Laboratory OS to download and run Mistral 7B OpenOrca using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
OpenOrca / Mistral 7B OpenOrca
Mistral 7B OpenOrca is a fine-tuned language model developed by OpenOrca using the Mistral 7B base architecture and the OpenOrca dataset. The model employs explanation tuning methodology inspired by Microsoft's Orca paper, training on GPT-4 and ChatGPT-generated instruction-following traces to enhance reasoning capabilities. It demonstrates competitive performance across language understanding benchmarks while utilizing ChatML formatting for conversational interactions.
Explore the Future of AI
Your server, your data, under your control
Mistral-7B-OpenOrca, often referred to as MistralOrca, is an open-source generative language model developed by Open-Orca through fine-tuning the Mistral 7B base model. The development of Mistral-7B-OpenOrca was grounded in the methodology introduced in Microsoft Research’s Orca paper, which explores progressive learning from complex explanation traces of large language models such as GPT-4. By leveraging datasets constructed to mirror sophisticated reasoning and explanation tasks, Mistral-7B-OpenOrca seeks to enable smaller models to achieve stronger reasoning, instruction-following, and conversational abilities through imitation learning.
Nomic Atlas map visualization of the OpenOrca dataset. This visualization summarizes the structure and diversity of the data used for fine-tuning Mistral-7B-OpenOrca.
Mistral-7B-OpenOrca is built by fine-tuning the Mistral 7B architecture using the OpenOrca dataset, which is an open-source effort to replicate the approach of the Orca: Progressive Learning from Complex Explanation Traces of GPT-4 research. The base Mistral 7B model is a transformer-based large language model capable of efficient inference and instruction following. Fine-tuning was performed using the Axolotl training framework, with careful attention to both data packing and loss computation. During training, only those tokens generated by the teacher model (GPT-4) contributed to the optimization, allowing the model to focus on learning higher-quality, reasoning-centered traces.
The model employs OpenAI’s Chat Markup Language (ChatML) formatting with delimiters such as <|im_start|> and <|im_end|>, a structure which is compatible with Transformers chat templating. Tokenization is handled by the LLaMA Byte Pair Encoding (BPE) tokenizer, with an expanded vocabulary of 32,001 tokens due to the introduction of a dedicated padding token. To optimize memory and training efficiency, input sequences were concatenated using packing techniques up to a maximum sequence length of 2,048 tokens, reaching a packing factor of 2.7 examples per sequence.
Dataset and Explanation Tuning
The core training data for Mistral-7B-OpenOrca consists of the OpenOrca dataset, which combines GPT-4-augmented instruction-following traces and a larger pool of ChatGPT-generated responses. The dataset construction closely follows the experiments outlined in the Orca paper, providing 5 million ChatGPT responses (FLAN-5M) alongside 1 million GPT-4 responses (FLAN-1M). Critically, the dataset is enriched by “explanation tuning,” in which each query-response pair is supplemented by detailed, step-by-step explanations from advanced teacher models like GPT-4. This encourages the emergence of transparent, reasoned generation in the student model during fine-tuning.
Model training spanned four epochs using 8 A6000 GPUs over 62 hours. The data acquisition process took advantage of both GPT-4 and ChatGPT APIs under real-world rate and token limitations, and responses from GPT-4 were notably longer on average than those from ChatGPT. By structuring data collection in this way, the model demonstrates progressive learning; ChatGPT responses act as an intermediary teacher, further anchoring the model’s capabilities between GPT-4 quality and more accessible open-source models.
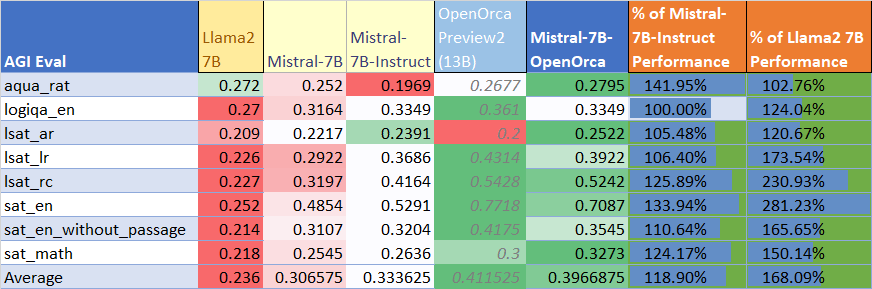
Detailed AGIEval benchmark comparison across Mistral-7B-OpenOrca and similar models, with color coding denoting relative performance.
Upon release, Mistral-7B-OpenOrca exhibited competitive results across a broad set of language understanding and reasoning benchmarks, and achieved high standing on the HuggingFace Open LLM Leaderboard. The model features an 8k context window and is designed to efficiently leverage moderate consumer acceleration capabilities.
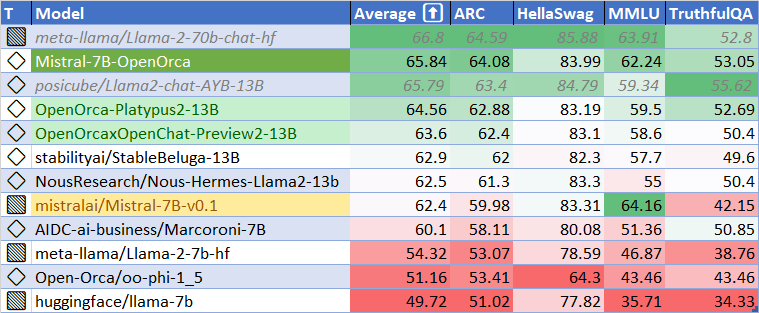
On standard evaluations, the model achieves an average score of 65.84 on major benchmarks (MMLU: 62.24, ARC: 64.08, HellaSwag: 83.99, TruthfulQA: 53.05), outperforming both its Mistral 7B base and other comparable 7B/13B models, and reaching up to 98.6% of Llama 2 70B Chat's leaderboard performance. Benchmark tools utilized include the Language Model Evaluation Harness.
HuggingFace Leaderboard results, displaying Mistral-7B-OpenOrca's comparative performance across a range of core language model benchmarks.
Further evaluation on the AGIEval suite demonstrated 129% of base Mistral-7B performance and 119% of Mistral-7B-Instruct on complex multidisciplinary reasoning tests, with parity observed in several areas when compared to much larger models.
Detailed AGIEval benchmark results showing category-wise performance across systems.
Notably, the model excelled in formal reasoning, causal judgment, and translation error detection, and exceeded previous instruction-tuned model results on roles requiring semantic and temporal understanding.
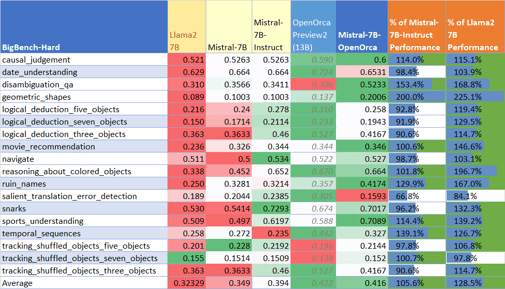
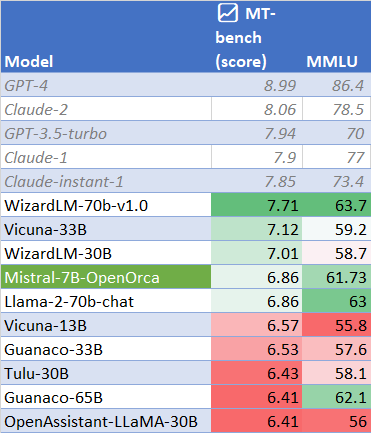
On the BigBench-Hard benchmark, the model showed strong results in entailment, disambiguation, and temporal reasoning tasks, and matched or surpassed ChatGPT in several aggregate scores. The MT-bench evaluation indicates performance on par with models like Llama 2 70B Chat (average score: 6.86).
MT-Bench and MMLU scores comparing Mistral-7B-OpenOrca with other large language models.
Safety assessments revealed Mistral-7B-OpenOrca to be more truthful in responses than models such as Vicuna 13B, while generating less toxic content when prompted adversarially.
Implementation Details and Usage
Mistral-7B-OpenOrca utilizes the ChatML prompt format for effective dialogue modeling. This approach is compatible with various libraries that support chat templating, including HuggingFace Transformers and text-generation-webui. Prompt messages are structured using system, user, and assistant roles, promoting clear conversational turns.
A typical prompt structure might look as follows:
[system] You are MistralOrca, a large language model trained by Alignment Lab AI. Write out your reasoning step-by-step to be sure you get the right answers!
[user] How are you?
[assistant] I am doing well!
[user] Please tell me about how mistral winds have attracted super-orcas.
Quantized versions, including AWQ, GPTQ, and GGUF formats, are available to facilitate more resource-efficient deployment and are maintained by the TheBloke profile on HuggingFace.
Limitations
Despite matched or near-matched performance compared to larger models in several benchmarks, Mistral-7B-OpenOrca shares common limitations with other models in the LLaMA family. These include susceptibility to hallucination, challenges with advanced reasoning (like mathematics or complex logic), and reduced world knowledge compared to models such as GPT-4. Its accuracy depends heavily on the training data distribution, and certain specialized domains or underrepresented topics may receive less robust performance. Though explanation tuning encourages transparency, the model’s internal reasoning remains largely opaque. Careful moderation is advisable when deploying for sensitive applications due to the potential for biased or harmful outputs.
Related Models and Licensing
Mistral-7B-OpenOrca is part of a broader ecosystem of open-source and instruction-finetuned models. It is directly derived from the Mistral 7B base. Related companion models include OpenOrcaxOpenChat-Preview2-13B and earlier work such as Microsoft’s Orca (13B). At the time of writing, the model’s licensing references the intention to comply with LLaMA’s release policy, with final details under review.